iptables revisited: a not so ordinary ‘firewall’

Source: Per Linde, Martynas Pumputis and Guillermo Rodr ́ıguez iptables revisited: a not so ordinary ‘firewall’
iptables revisited: Abstract
At the present time, security on the internet, and networks in general have evolved, and become an issue that should not be disregarded. It is well known that many experts recommend Linux as the main operating system for the machines that have to be in charge of security (also for a desktop computer). Linux included a basic firewall tool called ipchains in the series of its kernel until 2.4 version, though after that version it switched to iptables. iptables is known for its efficiency and functionality, but the enormous functionality means a more complex tool to be configured. This paper will overview some mechanisms to do advanced configuration of iptables based on two main scenarios. The different configurations presented will try to prove the remarkable power of iptables as an independent firewall and also as a tool that can work in conjuntion with other tools usually incorporated when included this one.
Introduction
iptables is a firewall developed by the Netfilter Project 1 . Presently, this firewall is becoming more and more popular (both among end users and network administrators). The popularity of this firewall it closely related to Linux operating system, because iptables works with Linux kernels 2.4 and 2.6 and almost every major Linux distribution comes with pre-installed iptables firewall. This firewall is also known as a stateful packet filter. It is a main difference between iptables and ipchains (an ancestor of iptables that was used with Linux kernel versions up to 2.4). The firewall supports not only a packet filtering, but it is also able to log, forward packets and it could be used together with such tools as psad, snort, etc. In this paper we will look a bit deeper into more advance iptables configurations, but first of all, we would like to introduce a reader to a basic usage of iptables. The core of the firewall consists of four parts [7]: tables, chains, matches and targets. A system administrator is able to define an iptables policy, i.e. tables of chains, which describe how a kernel should react against different groups of packets. Rules are used to create a chain – collection of rules that is applied to every packet. There are five predefined chains:
- INPUT: used for incoming packets before routing.
- OUTPUT: used for packets coming into the box itself.
- FORWARD: used for packets being routed through the box.
- PREROUTING: used for locally-generated packets before routing.
- POSTROUTING: used for packets as they about to leave iptables.
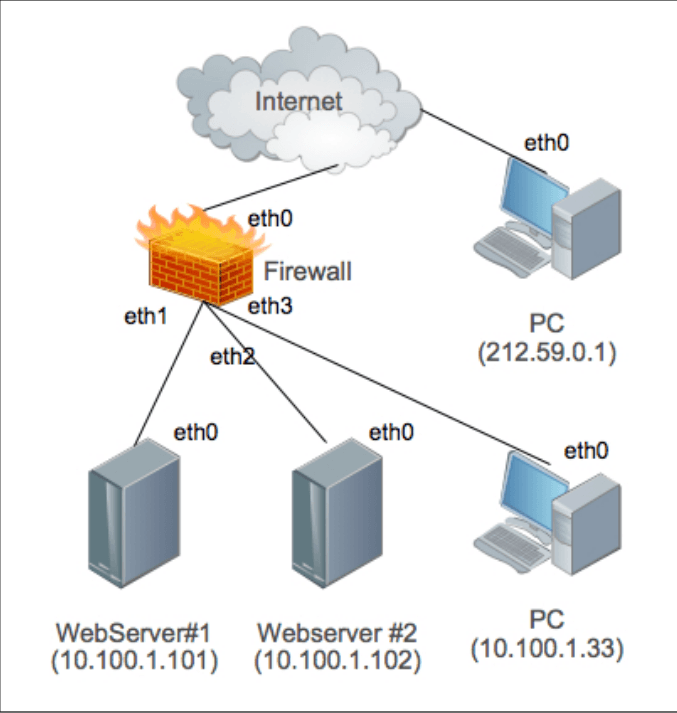
Every rule should have a set of matches, that helps to filter packets (e.g. -d 10.100.1.1 matches a destination IP 10.100.1.1), and it also has to have a target – an action which should be performed when a rule matches on a packet (e.g. ACCEPT, DROP, LOG…). All the examples presented in this paper (excluding the one used at section 6) will be based on the scenario presented in the figure 1. In the following scenario, WebServer#1 (10.100.1.101 assigned to its ‘eth0’ interface), WebServer#2 (10.100.1.102 assigned to its ‘eth0’ interface) and PC (10.100.1.33 assigned to its ‘eth0’ interface) belong to a local network and every packet that comes from the Internet/LAN is filtered by the firewall (‘eth1’ interface for LAN’s traffic, ‘eth0’ for Internet’s traffic). PC (212.59.0.1 assigned to ‘eth0’ interface) is reachable directly through the Internet. The listing 1 shows a couple of rules, the first one appends a rule to the end of the INPUT chain and it specifies that every packet from the source with IP address 212.59.0.1 will beDROPed and the second rule logs all outgoing connections from eth1 interface.
iptables -A INPUT -s 212.59.0.1 -j DROP iptables -A OUTPUT -o eth1 -j LOG
Matching patterns
Sometimes we want to filter (drop) packets that contain some bad content (for example .exe files, packets with wrong IP headers). In such case “string” extension could be used. It allows to match a string with a packet’s payload, as it shown in the listing 2, where the first rule is used to drop a packet that contains a ‘bad word’ string, and the second rule drops a packet that contains an executable file, .exe.
iptables -A INPUT -m string -- string ’ bad word ’ -- algo bm -j DROP iptables -A INPUT -m string -- string ’. exe ’ -- algo bm -j DROP
When we are filtering files by extensions, we should beware of a few issues:
- Usually files are splited into multiple packets (because of file size which is usually bigger than one packet size) and only one packet, which contains extension string, will be dropped.
- Also, some content that containt a string with file extension will be filtered.
Registering and debugging iptables’ actions In some cases it can be useful to log network events and in these cases the LOG target comes in handy. The LOG target can be used to log information about packets in a logfile, which can be useful for debugging or as evidence for a prohibited network activity. When a firewall script is being tested the administrator can use LOG as target instead of DROP in his rules. Test of the script can then be made fairly easy by observing the log files. The actual logging is handled by the syslogd which log sytem events to the file /var/log/messages, the messages can be read by using the command dmesg. With the LOG argument –log-prefix it is possible to attach a prefixstring to every entry, which will make it easier to find all relevant iptables entries (or automate the process by using the command grep). The log entries consist of packet data, like most of the IP-header and other interesting data.[2].
iptables -P INPUT LOG -- log - prefix " INPUT packets "
Constraining a connection
Regulating by time
In many networks there are regular server maintaining hours, this can include actions like backups, system updates and/or system scans. When these actions are being executed it can be necessary to redirect the traffic from the current server to another server. It can also be the case that some types of traffic should only be allowed during certain hours, so employees are able to get internet access only during lunch hours and no access or limited access during office hours. In listing 4, employers are allowed to browse the internet (HTTP(S)) during lunch hours. Note that traffic should be dropped by default.
iptables -A FORWARD -p tcp -m multiport -- dport http , https -o eth0 -i eth3 -m time -- timestart 12:00 -- timestop 13:00 -j ACCEPT
Listing 5 shows how all TCP/UDP traffic is dropped by default during service hours (between 02:00 and 03:00), that is for maintenance ’s tasks which should not be disrupted by incoming traffic.
iptables -A INPUT -p tcp -m time -- timestart 02:00 -- timestop 03:00 -j DROP iptables -A INPUT -p udp -m time -- timestart 02:00 -- timestop 03:00 -j DROP
Regulating by quota
In most systems a normal bandwidth usage can easily be calculated, if the bandwidth exceeds this level with some marginal it is possible that the traffic is unauthorized and should be limited. When using the quota rule the administrator can specify an amount of data that is allowed/disallowed or if a specific quota should be handled by one server and all other traffic by another. Listing 6 shows how a a quota of 10 Gb of HTTP traffic is allowed, and once this limit is reached the traffic is redirected to 10.100.1.102 which will return a page with the quota warning. iptables -A PREROUTING -p tcp — dport http -m quota 10737418240 -j ACCEPT iptables -A PREROUTING -p tcp — dport http -j DNAT –to – destination 10.100.1.102 One problem with iptables bandwidth monitoring is its counter, which is reset if the iptables service is restarted. Note also that the administrator in the example above have to reset the counter every month.
Limiting resource’s abuse
Another possibility to limit traffic thru the router is to use limit and iplimit. Limit specifies how many times per time unit an action are targeted, e.g. preventing SYN flooding. iplimit specifies how many connections from one IP number is targeted, e.g. one IP number should not be allowed to have more than 10 parallel connections to the router.
iptables -A INPUT -p TCP -- syn -m limit -- limit 5/ second -j ACCEPT
sdfdsf
iptables -A INPUT -p tcp -m state -- state NEW -m iplimit -- iplimit - under 10 -j ACCEPT
Load balancing
Presently, web servers should be able to handle lots of incoming connections. Load balancing feature could help for system administrators to cope with this problem. For example, our WebServers mirrors the Linux kernel project and all files could be accessed thru the port 21(ftp). The firewall that forwards packets to the servers, can also balance an incoming web traffic in two ways: by using n th (see lsiting 9 extension, which allows the firewall to match a particular received packet (n th ), or “random” (see listing 10 extension (which in the listing forwards packets randomly, with a probability of 50%, to each server’s ip).
iptables -A PREROUTING -i eth0 -p tcp -- dport 21 -m state --state NEW -m nth --counter 0 --every 2 --packet 0 -j DNAT --to-destination 10.100.1.101:21 iptables -A PREROUTING -i eth0 -p tcp -- dport 21 -m state --state NEW -m nth --counter 0 --every 2 --packet 1 -j DNAT --to-destination 10.100.1.102:21
iptables -A PREROUTING -i eth0 -p tcp -- dport 21 -m state --state NEW -m random --average 50 -j DNAT --to-destination 10.100.1.101:21 iptables -A PREROUTING -i eth0 -p tcp -- dport 21 -m state --state NEW -m random --average 50 -j DNAT --to-destination 10.100.1.102:21
Shaping traffic flows
In this section we present a ‘joint-venture’ between iptables and a set of tools to shape traffic called tc (Traffic Control). These traffic control tools provide the user of a system with the ability to adjust any kind of traffic flows. The tools are quite powerfull in the sense that the control over the queues, and different components and queuing algorithms involved in a network device is very high. Traffic control focuses on QoS (Quality of Service) by categorizing flows of packets into queues according to a set of rules (filter policies). The reasoning behind QoS is that bandwith is a limited resource and an expensive one. Some services and applications need to be prioritized, guaranteed a minimum quality of service to operate as specified by a policy or an agreement, or have their bandwith usage limited. It is important to reflect that not all flows can be shaped, outgoing flows can be completely shaped, however, incoming flows can be partially shaped. The explanation is that a user has control over the traffic being sent through a netwrok device because it’s either produced or forwarded from other systems (that use this one as a gateway) but it is not possible to limit the traffic received through a network device since there is no way to tell 2 the source of this traffic to stop or limit the flow. Incoming flows can be partially shaped because the path between the network device and the destination service is within the system’s boundaries and so it can ‘virtually’ be shaped. Traffic control not only is useful to shape traffic but also to protect a system (or a network) against SYN flood attacks and Denial of Service attacks because it is very difficult to distinguish between legit requests than those aimed to take a service out in a system, and so a shape of the connections abusing the services can help minimize the effects instead of shutting down the service.
Scenario
The sample set up that will be used for this section is a file server used as a public HTTP/FTP/RSYNC server of open source software. This system has a full-duplex 100mbps link shared with some others systems within a small domain, and this domain is inside a bigger network (University’s). Given the purpose of this system, anyone can access to it to retrieve a file. However, in the last year, the system has experienced a sudden increase of traffic which hogs the system most of the system. Since there was no traffic policies, a connection within the internal domain was not distinguished between a connection within the University’s network nor outside the University’s. An initial solution to increase performance (and also bandwith) for the other systems within the server’s network was put in place, and it consisted in a limit of 70% on the outgoing stream (70mbps). Although this solution was supposed to be temporary, it became a policy and has not changed. However, there is a need to distinguish traffic within system’s network, traffic within University’s network and traffic from outside University. Due to the purpose of the system, many servers within the University use this system to update their operating systems(and also many people use it to get their favourite latest Linux distribution), and so they should be prioritized over other connections. The solution that is going to be presented prioritizes server’s network traffic over University’s, and these two are prioritized over traffic from outside University (with some exceptions), it also tries to provide a fast response to any establishing connection and fairness between connections shall be a must (if two or more connections are shaped according to a rule, each one will be treated equally).
(Brief ) introduction to tc
Given the aim of this paper and its focus on iptables, in this subsection tc will not be discussed in detail, we refer to the excellent guide by Hubert et al. about advanced routing and traffic control under Linux for the areas not covered here [1]. Since packet-switched networks (widely used nowadays) are stateless, there is no way to distiinguish between flows. Traffic control introduces ‘some’ statefulness using packets’ properties to administer them and organize them into queues with different policies. tc schedules traffic into queues called . Each qdisc must have a handler algorithm (FIFO, HTB, SQF, CBQ) [5], called the queueing displicine (FIFO is the default discipline) [3]. There are two types of qdisc, classful and classless, the formers can contain classes and the latters cannot contain classes. The organisation of queues and classes is usually seen as a tree where the leaf nodes are terminal classes containing a qdisc. tc also provides filtering mechanisms to classify (and also apply a policy) packets based on their attributes (the classifier that will be able to do this is called u32). This feature is very important because it is what will let us move packets arriving to root qdisc to the defined classes and qdiscs[4]. In our scenario, shown in figure 2, there are four main classes (each is represented as a green circle) attached to a root 3 class node. ‘High priority’ class will handle ICMP and most of establishing connection packets, ‘Internal’ class will handle system’s network and University’s network (see their subclasses), ‘External’ will handle HTTP, FTP and RSYNC traffic (see their subclasses) whose source or destination is not within University’s network (which includes system’s network), and ‘Default’ will handle any other traffic. Since tc does not use names, each class has a numerical identifier (e.g. RSYNC class has the identifier “1:33”), and atttached to each class there is a qdisc, though this is not represented in the diagram but the algorithm is (e.g. for the same class RSYNC, the algorithm used is SQF). The range next to each class represents the guaranteed rate and the maximum rate, both in mbps, that each class is allowed to use (e.g. RSYNC’s class can use up to 75mbps and has a guaranteed bandwith of 20mbps). 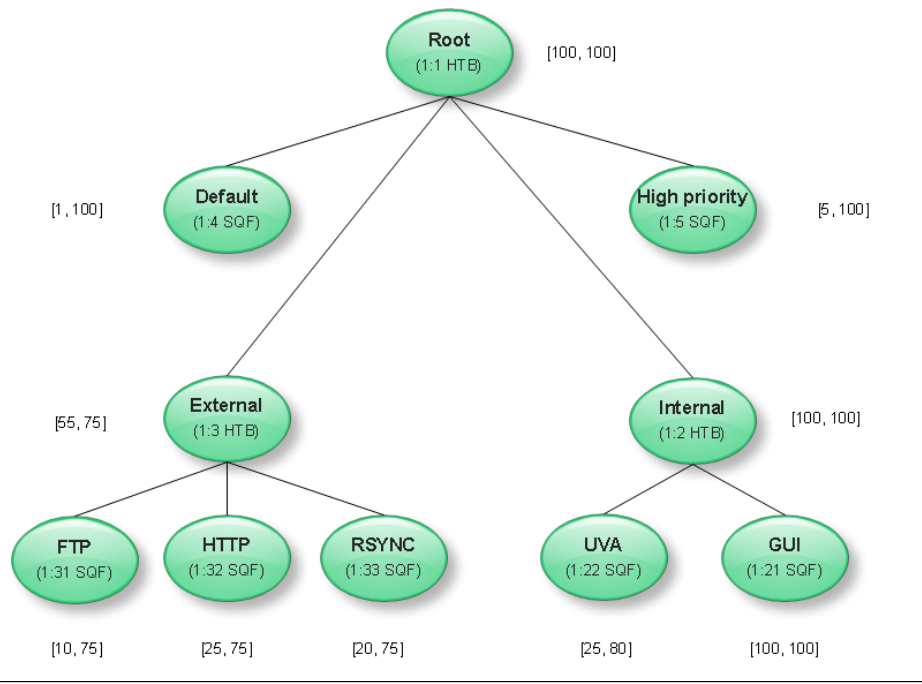 An example of the configuration of the class and its attached qdisc for ‘High priority’ traffic is shown in listing 11. Note that it also includes the filter that classifies traffic at the top of the tree (root) based on the id ‘5’ into the defined qdisc.
An example of the configuration of the class and its attached qdisc for ‘High priority’ traffic is shown in listing 11. Note that it also includes the filter that classifies traffic at the top of the tree (root) based on the id ‘5’ into the defined qdisc.
tc class add dev eth0 parent 1:1 classid 1:5 htb rate 5 mbit ceil 100 mbit tc qdisc add dev eth0 parent 1:5 handle 5: sfq perturb 10 tc filter add dev eth0 parent 1:0 prio 0 protocol ip handle 5 fw flowid 1:5
Flagging packets with iptables’s ‘mangle’ table
The introduction described how iptables works and its internals as presented in figure 3. This subsection will focus in the non-default 4 table of iptables, mangle, whose use is for “specialized packet alteration”. ‘mangle’ table has five chains (see figure 3) is mostly used to flag packets according to the characteristics we want to mark somehow the packets to match, though they can also be altered with other targets. The target used to flag packets is MARK. The mark is a numerical value (either decimal or hexadecimal) that is set with the option –set-mark value. The characteristics can be obtained from the packet by analysing its parameters (source/destination address/port, protocol, flags,…) or using a packet classifier module for iptables called layer7 5 . This kind of classifiers analyse packet’s application layer data instead of analysing what the built-in classifiers match: IP, protocol, port, flag,… As of now, this application layer packet shaping is quite accurate but for many protocols, specially those that try to obscure themselves to avoid this shaping, is slow (figuring the application used is more processor-consuming than reading a parameter from a packet). This special mark can be later used for rerouting a packet (if used in a chain before being routed), log it,… In our scenario, this mark will be used by the tc filters to classify the packets into the different classes so tc can shape the traffic according to the tree of classes and qdiscs that was defined in figure 2, and provide a quality of service as it was desired (and needed). The list of iptables’s rules used to flag different types of traffic according to figure 2 is shown in listing 12. To make sure that traffic is shaped, it’s flagged in the POSTROUTING chain of the ‘mangle’ table (the first rule creates a chain linked to the POSTROUTING chain). Note that ICMP, UDP and TCP-flag rules are considered of high priority, the target RETURN is used to make sure that once the packet matches one entry it returns to the calling chain and the mark’s values are in hexadecimal.
iptables -t mangle -A POSTROUTING -o eth0 -j SHAPER iptables -t mangle -A SHAPER -p icmp -m comment --comment "ICMP (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p icmp -j RETURN iptables -t mangle -A SHAPER -p udp -m comment --comment "UDP (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p udp -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK FIN, ACK -m comment --comment "FIN, ACK (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK FIN, ACK -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK SYN, ACK -m comment --comment "SYN, ACK (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK SYN, ACK -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK RST, ACK -m comment --comment "RST, ACK (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK RST, ACK -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK RST -m comment --comment "RST (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK RST -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK SYN -m comment --comment "SYN (High priority)"-j MARK --set -mark 0x5 iptables -t mangle -A SHAPER -p tcp -m tcp --tcp -flags FIN, SYN, RST, ACK SYN -j RETURN iptables -t mangle -A SHAPER -d 157.88.36.0 / 255.255.255.0 -m comment --comment "GUI (Internal)"-j MARK --set -mark 0x15 iptables -t mangle -A SHAPER -d 157.88.36.0 / 255.255.255.0 -j RETURN iptables -t mangle -A SHAPER -d 157.88.0.0 / 255.255.0.0 -m comment --comment "UVa (Internal)"-j MARK --set -mark 0x16 iptables -t mangle -A SHAPER -d 157.88.0.0 / 255.255.0.0 -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --sport 20:21 -m comment --comment "FTP (External)"-j MARK --set -mark 0x1f iptables -t mangle -A SHAPER -p tcp -m tcp --sport 20:21 -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --sport 49152:65534 -m comment --comment "FTP (External)"-j MARK --set -mark 0x1f iptables -t mangle -A SHAPER -p tcp -m tcp --sport 49152:65534 -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --sport 80 -m comment --comment "HTTP (External)"-j MARK --set -mark 0x20 iptables -t mangle -A SHAPER -p tcp -m tcp --sport 80 -j RETURN iptables -t mangle -A SHAPER -p tcp -m tcp --sport 873 -m comment --comment "RSYNC (External)"-j MARK --set -mark 0x21 iptables -t mangle -A SHAPER -p tcp -m tcp --sport 873 -j RETURN iptables -t mangle -A SHAPER -m comment --comment "Any (Default)"-j MARK --set -mark 0x4 iptables -t mangle -A SHAPER -j RETURN
Protection against SYN-floods and ICMP DoS
tc and iptables can be used to protect a system or a network from a SYN-flood attack or an ICMP DoS 6 . Usually, the solution taken is blocking the source IP(s) but this means that there must be some kind of warning system in place. If traffic is intercepted before it reaches a certain service of a system, it can be shaped once a threshold has been reached and limited so it does not block the service, though it will likely affect ‘legit’ connections as well [1]. The following listing, 13, shows how an ICMP DoS can be intercepted and shaped if the threshold established is reached. iptables will accept ICMP packet at a rate of 25 per second, and in bursts of 5, if this threshold is not reached, then these packets are flagged with a ‘5’ (and later shaped according to this mark), if the threshold is reached, then they are marked with a ‘4’ (which will probably be a very low priority, and limited bandwith, queue in tc).
iptables --t -mangle --A -INPUT --p -icmp --m -limit -- limit 25/ s -- limit - burst 5 -j MARK -- set - mark 0 x5 iptables --t -mangle --A -INPUT --p -icmp --m -limit -- limit 25/ s -- limit - burst 5 -j RETURN iptables --t -mangle --A -INPUT --p -icmp --j -MARK -- set - mark 0 x4 iptables --t -mangle --A -INPUT --p -icmp --j -RETURN
Similarly, the listing 14 shows what it is done to intercept a SYN-flood attack (instead of using the option –tcp-flags, an option which takes care of matching all SYN packets is used, –syn).
iptables -t mangle -A INPUT -p tcp --syn -m limit --limit 150/ s --limit -burst 10 -j MARK --set -mark 0 x5 iptables -t mangle -A INPUT -p tcp --syn -m limit --limit 150/ s --limit -burst 10 -j RETURN iptables -t mangle -A INPUT -p tcp --syn -j MARK --set -mark 0x4 iptables -t mangle -A INPUT -p tcp --syn -j RETURN
Conclusion
Regular firewalls focus on port forwarding and port filtering, but this is not enough for a network connected to the malicious internet. Desktop computers are often equipped with protection applications like anti-virus and anti-malware, but many network threats cannot be avoided by these. A good and well configured firewall on the other hand can stop many network threats before they have a chance to get into the local network, such a firewall can even stop some virus threats. It is our opinion that iptables is a good firewall with enormous potential, to secure both small and big networks because it satisfies all special needs of the network’s computers and servers. iptables can be configured in many different ways, e.g. to load-balance traffic over several mirrored servers (see 9 and 10) to even out traffic load; use flow-control to prioritize (among others) traffic (see fig. 2); use regulation rules to limit all or just some types of traffic, for example, the limit can be time (see 4), traffic amount (see 6) or occurrences (see 7). When creating a new iptables configuration it can be of good practice using the LOG because this will make debugging and testing easier; and it can also be used later to analyze some minor “holes” or improve the existing rules. iptables is a complex tool that satisfies all firewalling needs (almost), but one should notice that a complex tool such as iptables demands “know-how”. Without proper knowledge on iptables configuration, what it was supposed to secure a network or a system can easily become into a serious security vulnerability; a novice user should always have in mind to set the target DROP by default 7 in the INPUT chain, rather than writing specific rules to DROP. There are commercial solutions from many vendors like Cisco, Avaya, Juniper,… but iptables is capable of doing the same job as the tools offered by these companies, which usually are closed source projects, and makes the use of these solutions more expensive than iptables since it is open source tool (free for all).
References
[1] Hubert, B. and Graf, T. and Maxwell, G. and van Mook, R. and van Oosterhout, M. and Schroeder, P. and Spaans, J. and Larroy, P., Linux advanced routing & traffic control. Ottawa Linux Symposium, 2003. [2] Andreasson, O., Iptables Tutorial 1.2.2.
http://iptables-tutorial.frozentux.net/iptables-tutorial.html
[3] Singletary, D., ADSL Bandwidth Management HOWTO.
http://www.tldp.org/HOWTO/ADSL-Bandwidth-Management-HOWTO/