Source: CyberPunk
What is a Firewall ?
A firewall is a system that provides network security by filtering incoming and outgoing network traffic based on a set of user-defined rules. In general, the purpose of a firewall is to reduce or eliminate the occurrence of unwanted network communications while allowing all legitimate communication to flow freely. In most server infrastructures, firewalls provide an essential layer of security that, combined with other measures, prevent attackers from accessing your servers in malicious ways.
A firewall typically establishes a barrier between a trusted, secure internal network and another outside network, such as the Internet, that is assumed to not be secure or trusted. Firewalls are often categorized as either network firewalls or host-based firewalls. Network firewalls are a software appliance running on general purpose hardware or hardware-based firewall computer appliances that filter traffic between two or more networks. Host-based firewalls provide a layer of software on one host that controls network traffic in and out of that single machine. Routers that pass data between networks contain firewall components and can often perform basic routing functions as well, Firewall appliances may also offer other functionality to the internal network they protect such as acting as a DHCP or VPN server for that network.
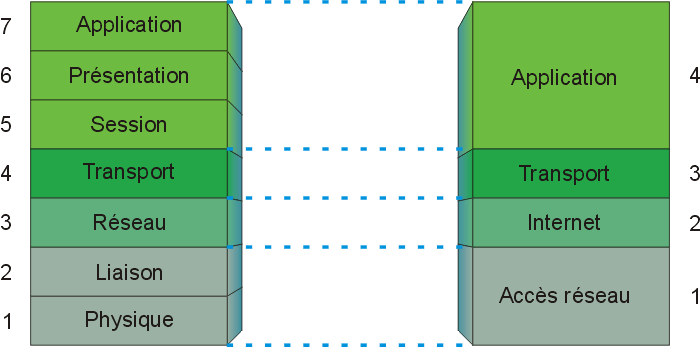
TCP network traffic moves around a network in packets, which are containers that consist of a packet header—this contains control information such as source and destination addresses, and packet sequence information—and the data (also known as a payload). While the control information in each packet helps to ensure that its associated data gets delivered properly, the elements it contains also provides firewalls a variety of ways to match packets against firewall rules.
It is important to note that successfully receiving incoming TCP packets requires the receiver to send outgoing acknowledgment packets back to the sender. The combination of the control information in the incoming and outgoing packets can be used to determine the connection state (e.g. new, established, related) of between the sender and receiver.
Types of Firewalls
There are different types of firewalls depending on where the communication is taking place, where the communication is intercepted and the state that is being traced.
Network layer or packet filters
Network layer firewalls, also called packet filters, operate at a relatively low level of the TCP/IP protocol stack, not allowing packets to pass through the firewall unless they match the established rule set. The firewall administrator may define the rules; or default rules may apply. The term “packet filter” originated in the context of BSD operating systems.
Network layer firewalls generally fall into two sub-categories, stateful and stateless.
Stateful firewalls
maintain context about active sessions, and use that “state information” to speed packet processing. Any existing network connection can be described by several properties, including source and destination IP address, UDP or TCP ports, and the current stage of the connection’s lifetime (including session initiation, handshaking, data transfer, or completion connection). If a packet does not match an existing connection, it will be evaluated according to the ruleset for new connections. If a packet matches an existing connection based on comparison with the firewall’s state table, it will be allowed to pass without further processing.
Stateless firewalls
require less memory, and can be faster for simple filters that require less time to filter than to look up a session. They may also be necessary for filtering stateless network protocols that have no concept of a session. However, they cannot make more complex decisions based on what stage communications between hosts have reached.
Lire la suite…