Différents accès aux différentes organisations avec un pare-feu

Zone démilitarisée, la DMZ.
Une zone démilitarisée est un sous-réseau (DMZ) isolé par deux pare-feux (firewall). Ce sous-réseau contient des machines se situant entre un réseau interne (LAN – postes clients) et un réseau externe (typiquement, Internet).
La DMZ permet à ces machines d’accéder à Internet et/ou de publier des services sur Internet sous le contrôle du pare-feu externe. En cas de compromission d’une machine de la DMZ, l’accès vers le réseau local est encore controlé par le pare-feu interne.
La figure ci-contre représente un cas particulier de DMZ; pour des raisons d’économie, les deux pare-feu sont fusionnés. C’est la ‘colapsed dmz‘, moins sure, car dès que le pare-feu est compromis, plus rien n’est contrôlé.
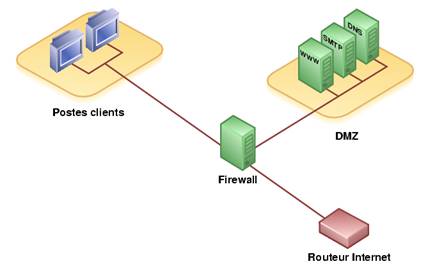
Schéma DMZ avec 1 seul pare-feu
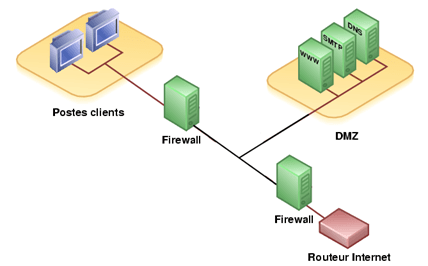
Schéma DMZ avec 2 pare-feux
une installation complète contient :
- Un réseau privé, dont on considère (souvent à tort) qu’il ne sera pas utilisé pour attaquer notre système informatique. Dans cette zone, il n’y a que des clients du réseau et des serveurs qui sont inaccessibles depuis l’Internet. Normalement, aucune connexion, au sens TCP du terme, aucun échange, au sens UDP du terme, ne peuvent être initiés depuis le Net vers cette zone.
- Une « DMZ » (Zone DéMilitarisée), qui contient des serveurs accessibles depuis le Net et depuis le réseau privé. Comme ils sont accessibles depuis le Net, ils risquent des attaques. Ceci induit deux conséquences :
- Il faut étroitement contrôler ce que l’on peut faire dessus depuis le Net, pour éviter qu’ils se fassent « casser » trop facilement,
- Il faut s’assurer qu’ils ne peuvent pas accéder aux serveurs de la zone privée, de manière à ce que si un pirate arrivait à en prendre possession, il ne puisse directement accéder au reste du réseau.
Le dispositif qui va permettre d’établir ces règles de passages s’appelle un pare-feu. Techniquement, ce pourra être un logiciel de contrôle installé sur un routeur.
1.1 Les trois passages.
1.1.1 Entre le réseau privé et le Net.
Toujours typiquement, ce sont les clients du réseau (les utilisateurs) à qui l’on va donner des possibilités d’accéder au Net comme par exemple le surf ou la messagerie. Toutes les requêtes partent du réseau privé vers le Net. Seules les réponses à ces requêtes doivent entrer dans cette zone. Les accès peuvent être complètement bridés (les clients du réseau privé n’ont aucun droit d’accès vers le Net, ça nuit à leur productivité.
Seul le patron y a droit). Ou alors, les utilisateurs ne pourront consulter qu’un nombre de sites limités, dans le cadre de leurs activités professionnelles exclusivement. Très généralement, cette zone est construite sur une classe d’adresses privées et nécessite donc une translation d’adresse pour accéder au Net. C’est le routeur qui se chargera de cette translation.
1.1.2 Entre la DMZ et le Net.
Ici, nous avons des serveurs qui doivent être accessibles depuis le Net. Un serveur Web, un serveur de messagerie, un FTP… Il faudra donc permettre de laisser passer des connexions initiées depuis l’extérieur. Bien entendu, ça présente des dangers, il faudra surveiller étroitement et ne laisser passer que le strict nécessaire.
Si l’on dispose d’adresses IP publiques, le routeur fera un simple routage. Si l’on n’en dispose pas, il devra faire du « port forwarding » pour permettre, avec la seule IP publique dont on dispose, d’accéder aux autres serveurs de la DMZ. Cette technique fonctionne bien sur un petit nombre de serveurs, mais devient très vite un casse-tête si, par exemple, plusieurs serveurs HTTP sont présents dans la DMZ.
1.1.3 Entre le réseau privé et la DMZ.
Les accès devraient être à peu près du même type qu’entre la zone privée et le Net, avec un peu plus de souplesse. En effet, il faudra
- Mettre à jour les serveurs web,
- Envoyer et recevoir les messages, puisque le SMTP est dedans
- Mettre à jour le contenu du FTP (droits en écriture).
En revanche, depuis la DMZ, il ne devrait y avoir aucune raison pour qu’une connexion soit initiée vers la zone privée.
La NAT.
2.1 Principe du NAT.
Le mécanisme de translation d’adresses (en anglais Network Address Translation noté NAT) a été mis au point afin de répondre à la pénurie d’adresses IP avec le protocole IPv4 (le protocoleIPv6 répondra à terme à ce problème).
En effet, en adressage IPv4 le nombre d’adresses IP routables (donc uniques sur la planète) n’est pas suffisant pour permettre à toutes les machines le nécessitant d’être connectées à internet.
Le principe du NAT consiste donc à utiliser une passerelle de connexion à internet, possédant au moins une interface réseau connectée sur le réseau interne et au moins une interface réseau connectée à Internet (possédant une adresse IP routable), pour connecter l’ensemble des machines du réseau.
Il s’agit de réaliser, au niveau de la passerelle, une translation (littéralement une « traduction ») des paquets provenant du réseau interne vers le réseau externe.
Ainsi, chaque machine du réseau nécessitant d’accéder à internet est configurée pour utiliser la passerelle NAT (en précisant l’adresse IP de la passerelle dans le champ « Gateway » de ses paramètres TCP/IP). Lorsqu’une machine du réseau effectue une requête vers Internet, la passerelle effectue la requête à sa place, reçoit la réponse, puis la transmet à la machine ayant fait la demande.
Étant donné que la passerelle camoufle complètement l’adressage interne d’un réseau, le mécanisme de translation d’adresses permet d’assurer une fonction de sécurisation. En effet, pour un observateur externe au réseau, toutes les requêtes semblent provenir de l’adresse IP de la passerelle.


Fig2. Présentation de la translation d’adresse par la Nat.
2.2 Implémentation du NAT.
Pour faire correspondre les adresses internes avec un groupe d’adresses externes, on se sert d’une table. Celle ci contient des paires (adresse interne, adresse externe (traduite)). Quand l’adresse interne émet une trame qui traverse le routeur qui NAT, cette adresse est remplacée dans l’entête du paquet TCP/IP par son adresse IP externe. Le remplacement inverse sera fait quand une trame vers cette adresse externe doit être traduite en IP interne.
Aussi, on peut réutiliser une entrée dans la table de correspondance du NAT si aucun trafic avec ces adresses n’a traversé le routeur pendant un certain temps (paramétrable).
| IP interne | IP externe | Durée (s) | Réutilisable ? |
| 10.101.10.20 | 193.48.100.174 | 1200 | non |
| 10.100.54.271251 | 193.48.101.8 | 3601 | oui |
| 10.100.0.89 | 193.48.100.46 | 0 | non |
Voici par exemple une table de NAT simplifiée. On supposera qu’une entrée pourra être réclamée si la traduction n’a pas été utilisée depuis plus de 3 600 secondes.
La première ligne indique que la machine interne, possédant l’adresse IP 10.101.10.20 est traduite en 193.48.100.174 quand elle converse avec le monde extérieur. Elle n’a pas émis de paquet depuis 1200 secondes, mais la limite étant 3600, cette entrée dans la table lui est toujours assignée. La seconde machine est restée inactive pendant plus de 3600 secondes, peut-être qu’elle est éteinte, une autre machine peut reprendre cette entrée (en modifiant la première colonne puisqu’elle n’aura pas la même IP interne). Enfin, la dernière machine est actuellement en conversation avec l’extérieur, le champ Duré étant 0.
Actuellement, la plupart des pare-feux et routeurs possèdent cette caractéristique. Elle est par exemple utilisée par les abonnés ADSL qui connectent plusieurs ordinateurs sur une ligne unique.
2.3- Différents types de NAT.
2.3.1 NAT statique.
Où un ensemble d’adresses internes est traduit dans un ensemble de même taille d’adresses externes. Ces NAT sont dites Statiques car l’association entre une adresse interne et son homologue externe est statique (première adresse interne avec première externe…). La table d’association est assez simple, de type un pour un et ne contient que des adresses. Ces NAT servent à donner accès à des serveurs en interne à partir de l’extérieur.
Il existe trois types de NAT Statiques :
- NAT Statique Unidirectionnelle qui traduisent uniquement les connexions de l’extérieur vers l’intérieur (attention, les paquets de retour sont aussi traduits). Le plus souvent lorsque la machine interne initie une connexion vers l’exterieur la connexion est traduite par une autre NAT dynamique.
- NAT Statique Bidirectionnelle qui traduisent les connexions dans les deux sens.
- NAT Statique PAT (Port Address Translation du port serveur). Conjonction d’une NATStatique Uni ou Bidirectionnelle et d’une transformation du port serveur. (Remarque: le nomPAT vient du fait que le port serveur/destination est modifié. À ne pas confondre avec la NATDynamique PAT).
2.3.2 NAT dynamique.
Où un ensemble d’adresses internes est traduit dans un plus petit ensemble d’adresses externes. Ces NAT sont dites Dynamiques car l’association entre une adresse interne et sa contre-partie externe est créée dynamiquement au moment de l’initiation de la connexion. Ce sont les numéros de ports qui vont permettre d’identifier la traduction en place : le numéro du port source (celui de la machine interne) va être modifié par le routeur. Il va servir pour identifier la machine interne.
Il existe plusieurs types de NAT Dynamiques :
- NAT Dynamique PAT (Port Address Translation du port client/source) ou les adresses externes sont indifférentes (le plus souvent la plage d’adresse que votre fournisseur d’accès vous a attribuée). (Remarque: le nom PAT vient du fait que le port source est modifié. À ne pas confondre avec la NAT Statique PAT).
- Masquerading où l’adresse IP du routeur est seule utilisée comme adresse externe. LeMasquerading est donc un sous cas de la Dynamique PAT.
- NAT Pool de Source est la plus vieille des NAT. La première connexion venant de l’intérieur prend la première adresse externe, la suivante la seconde, jusqu’à ce qu’il n’y ait plus d’adresse externe. Dans ce cas exceptionnel le port source n’est pas modifié. Ce type de NAT n’est plus utilisé.
- NAT Pool de Destination permet de faire de la répartition de charge entre plusieurs serveurs. Peu d’adresses externes sont donc associées avec les adresses internes des serveurs. Le pare-feuse débrouille pour répartir les connexions entre les différents serveurs.

Fig2. Présentation de la translation d’adresse par la Nat.
2.4 Bénéfices du NAT.
Les adresses internes peuvent être choisies parmi les adresses définies dans la RFC 1918. Ainsi plusieurs sites peuvent avoir le même adressage interne et communiquer entre eux en utilisant ce mécanisme. Étant donné que les adresses internes sont réutilisées, on économise des adresses IP, dont l’occupation, en IPv4, arrive à saturation.
On peut avoir moins d’adresses dans l’ensemble des adresses traduites que ce qu’on a comme adresses IP à l’intérieur du réseau, si l’on met en place un mécanisme permettant de récupérer des adresses inutilisées après un certain temps (on appelle ceci un « bail »). Plus précisément, si une entrée dans la table des traductions n’est pas utilisée pendant un certain temps (paramétrable dans le serveur DHCP du réseau), cette entrée peut-être réutilisée : une autre machine avec une adresse interne va récupérer l’adresse externe.
Le NAT masquant l’adresse IP de la machine interne, participe ainsi à la sécurité du site.
2.5 Problèmes inhérents.
Le problème majeur se pose lorsqu’un protocole de communication transmet l’adresse IP de l’hôte source dans un paquet. Cette adresse n’étant pas valide après avoir traversé le routeur NAT, elle ne peut être utilisée par la machine destinatrice. Ces protocoles sont dit « à contenu sale » ou « passant difficilement les pare-feux » car ils échangent au niveau applicatif (FTP) des informations du niveau IP (échange d’adresses) ou du niveau TCP (échange de ports). Ce qui transgresse le principe de la séparation des Couches réseaux.
Quelques protocoles « à contenu sale »: FTP en mode passif, H.323, les protocoles faisant du peer2peer(IRC-DCC), les protocoles de gestion de réseau (DNS, certains messages ICMP, traceroute)
Pour une liste plus exhaustive , voir la Catégorie:Protocole réseau passant difficilement les pare-feux.
Pour pallier cet inconvénient, les routeurs NAT doivent savoir inspecter le contenu des paquets qui les traversent, et remplacer les adresses IP spécifiées par les adresses traduites. Notez que cela implique de recalculer la somme de contrôle et la longueur du paquet.
Le NAT ne fait que participer à la politique de sécurité du site, et ce n’est pas son objectif principal : une fois la traduction établie, elle est bidirectionnelle.
- Protocole réseau passant difficilement les pare-feu.
Certains protocoles, de par leur conception, ne passent pas ou difficilement les pare-feu. Ils peuvent poser des problèmes au niveau du filtrage ou au niveau de la traduction d’adresse réseau (NAT).
Pour contourner ce problème, la plupart des pare-feu doivent implémenter des ruses très complexes.
Ce problème est important au point qu’il existe plusieurs RFC dont la RFC 3235 qui décrivent comment concevoir un protocole compatible avec les pare-feux.
3.1 Problème 1: échange de donnée IP dans le protocole.
Certains protocoles échangent au niveau applicatif (FTP…) des adresses IP qui ne devraient circuler qu’au niveau réseau (IP) ou des ports qui ne devraient circuler qu’au niveau transport(TCP/UDP). Ces échanges transgressent le principe de la séparation des couches réseaux(transgressant par la même occasion la RFC[6] 3235).
L’exemple le plus connu est FTP en mode actif qui échangent entre le client et le serveur des adresses IP ou des ports TCP/UDP.
Les données échangées au niveau applicatif ne sont pas traduites. Ces données échangées n’étant pas valides après avoir traversé le routeur NAT, elle ne peuvent être utilisées par la machine destinataire.
Pour cette raison, ces protocoles passent difficilement voire pas du tout, les règles de NAT.
3.2 Problème 2: protocole difficilement prévisible au niveau ports.
Certains protocoles utilisent de larges plages de ports. En effet ils décident des ports dynamiquement, échangent les nouveaux ports au niveau applicatif (cf précédente section) puis ouvrent de nouvelles connexions vers ces ports.
Ainsi, lorsqu’un administrateur définit la politique de filtrage de son pare-feu, il a beaucoup de difficultés à spécifier les ports en cause. Dans le pire des cas il est obligé d’ouvrir plein de ports, permettant par la même occasion d’autres protocoles.
Par exemple le protocole TFTP échange des numéros de ports ouverts sur la machine cliente. Le serveur TFTP s’en sert pour ouvrir des datagrammes vers le client. Ces datagrammes ont un port source et un port destination indéterminé. Donc, pour laisser passer TFTP, il faut laisser passer presque tout UDP entre les deux machines.

Fig2. Réseau client, serveur TFTP.
3.3 Problème 3: protocole ouvrant des connexions du serveur vers le client.
Dans la définition d’un protocole, celui qui initie la communication est le client, celui qui est en attente est le serveur. La plupart des protocoles sont constitués de une ou plusieurs connexions (socket ou datagramme) du client au serveur, la première étant appellé maître. Mais certains protocoles contiennent des connexions secondaires initiées du serveur vers le client.
3.4 Solution.
La seule solution pour filtrer et natter correctement un protocole « à contenu sale » est de faire de l’inspection applicative. La plupart des types de pare-feu sait inspecter un nombre limité d’applications. Chaque application est gérée par un module différent que l’on peut activer ou désactiver pour gagner en performance ou en cas de bug publié. La terminologie pour le concept de module d’inspection est différente pour chaque type de pare-feu:
- Conntrack sur Linux Netfilter
- CBAC sur Cisco IOS
- Fixup puis inspect sur Cisco PIX
- ApplicationLayerGateway sur Proventia M,
- Deep Packet Inspection sur Qosmos
- Predefined Services sur Juniper ScreenOS
- Deep Packet Inspection sur Check Point FireWall-1
Pour des raisons de sécurité, les pare-feu logiciels BSD (Ipfirewall, IPFilter et Packet Filter) ne font pas d’inspection de service dans le noyau. En effet l’inspection de service étant complexe, tout bug pourrait permettre la prise de contrôle de la machine. Pour faire de l’inspection de service, il faut dans ce cas installer un proxy qui lui tourne en espace utilisateur.
Les modules d’inspection applicative ont deux actions qui corrigent les deux problèmes:
- Ils traduisent les adresses IP et les ports échangés au niveau applicatif.
Cela permet de natter les protocoles en cause. - Ils autorisent dynamiquement les sockets ou datagrammes secondaires du protocole.
Il suffit par exemple d’autoriser TCP vers le port 21 pour autoriser FTP, la socket vers le port 20 étant automatiquement autorisée.
Cela permet de filtrer les protocoles en cause sans autoriser de gros intervalles de ports.
3.5 Quelques exemples.
- quelques vieux protocoles de transfert de fichier: FTP en mode passif, TFTP
- h523
- les protocoles faisant du peer2peer: IRC-DCC
- les protocoles de gestion de réseau: DNS, certains messages icmp, traceroute
3.6 La vraie solution.
La vraie solution est de concevoir le protocole en respectant toute une liste de règles. La RFC 3235 « Network Address Translator (NAT)-Friendly Application Design Guidelines » décrit comment élaborer un protocole passant la NAT sans difficulté.
4. Le Proxy
4.1 Introduction
Un serveur proxy (traduction française de «proxy server», appelé aussi «serveur mandataire») est à l’origine une machine faisant fonction d’intermédiaire entre les ordinateurs d’un réseau local(utilisant parfois des protocoles autres que le protocole TCP/IP) et internet.
La plupart du temps le serveur proxy est utilisé pour le web, il s’agit alors d’un proxy HTTP. Toutefois il peut exister des serveurs proxy pour chaque protocole applicatif (FTP, …).
4.2 Comment ça marche ?
En tapant une adresse comme http://www.yahoo.com/index.html, votre ordinateur va se connecter sur le serveur www.yahoo.com et demander la page index.html.

Fig1. Connection internet.
Avec un proxy, quand vous tapez http://www.yahoo.com/index.html, votre ordinateur va se connecter au proxy et lui demande d’aller chercher la page sur www.yahoo.com.

Fig1. Connection internet qui passe par un proxy.
4.3 Les fonctionnalités d’un serveur proxy.
Désormais, avec l’utilisation de TCP/IP au sein des réseaux locaux, le rôle de relais du serveur proxy est directement assuré par les passerelles et les routeurs. Pour autant, les serveurs proxy sont toujours d’actualité grâce à un certain nombre d’autres fonctionnalités.
4.3.1 La fonction de cache.
La plupart des proxys assurent ainsi une fonction de cache (en anglais caching), c’est-à-dire la capacité à garder en mémoire (en « cache ») les pages les plus souvent visitées par les utilisateurs du réseau local afin de pouvoir les leur fournir le plus rapidement possible. En effet, en informatique, le terme de « cache » désigne un espace de stockage temporaire de données (le terme de « tampon » est également parfois utilisé).
Un serveur proxy ayant la possibilité de cacher (néologisme signifiant « mettre en mémoire cache ») les informations est généralement appelé « serveur proxy-cache ».
Cette fonctionnalité implémentée dans certains serveurs proxy permet d’une part de réduire l’utilisation de la bande passante vers internet ainsi que de réduire le temps d’accès aux documents pour les utilisateurs.
Toutefois, pour mener à bien cette mission, il est nécessaire que le proxy compare régulièrement les données qu’il stocke en mémoire cache avec les données distantes afin de s’assurer que les données en cache sont toujours valides.
4.3.2 Le filtrage.
D’autre part, grâce à l’utilisation d’un proxy, il est possible d’assurer un suivi des connexions (en anglais logging ou tracking) via la constitution de journaux d’activité (logs) en enregistrant systématiquement les requêtes des utilisateurs lors de leurs demandes de connexion à Internet.
Il est ainsi possible de filtrer les connexions à internet en analysant d’une part les requêtes des clients, d’autre part les réponses des serveurs. Lorsque le filtrage est réalisé en comparant la requête du client à une liste de requêtes autorisées, on parle de liste blanche, lorsqu’il s’agit d’une liste de sites interdits on parle de liste noire. Enfin l’analyse des réponses des serveurs conformément à une liste de critères (mots-clés, …) est appelé filtrage de contenu.
4.3.3 L’authentification.
Dans la mesure où le proxy est l’intermédiaire indispensable des utilisateurs du réseau interne pour accéder à des ressources externes, il est parfois possible de l’utiliser pour authentifier les utilisateurs, c’est-à-dire de leur demander de s’identifier à l’aide d’un nom d’utilisateur et d’un mot de passe par exemple. Il est ainsi aisé de donner l’accès aux ressources externes aux seules personnes autorisées à le faire et de pouvoir enregistrer dans les fichiers journaux des accès identifiés.
Ce type de mécanisme lorsqu’il est mis en oeuvre pose bien évidemment de nombreux problèmes relatifs aux libertés individuelles et aux droits des personnes…
4.3.4 Les reverse-proxy.
On appelle reverse-proxy (en français le terme de relais inverse est parfois employé) un serveur proxy-cache « monté à l’envers », c’est-à-dire un serveur proxy permettant non pas aux utilisateurs d’accéder au réseau internet, mais aux utilisateurs d’internet d’accéder indirectement à certains serveurs internes.
Le reverse-proxy sert ainsi de relais pour les utilisateurs d’internet souhaitant accéder à un site web interne en lui transmettant indirectement les requêtes. Grâce au reverse-proxy, le serveur web est protégé des attaques directes de l’extérieur, ce qui renforce la sécurité du réseau interne. D’autre part, la fonction de cache du reverse-proxy peut permettre de soulager la charge du serveur pour lequel il est prévu, c’est la raison pour laquelle un tel serveur est parfois appelé » accélérateur « (server accelerator).
Enfin, grâce à des algorithmes perfectionnés, le reverse-proxy peut servir à répartir la charge en redirigeant les requêtes vers différents serveurs équivalents; on parle alors de répartition de charge(en anglais load balancing).
4.4 Mise en place d’un serveur proxy.
Le proxy le plus répandu est sans nul doute Squid, un logiciel libre disponible sur de nombreuses plates-formes dont Windows et Linux.
Sous Windows il existe plusieurs logiciels permettant de réaliser un serveur proxy à moindre coût pour son réseau local :
- Wingate est la solution la plus courante (mais non gratuite)
- la configuration d’un proxy avec Jana server devient de plus en plus courante
- Windows 2000 intègre Microsoft Proxy Server (MSP), complété par Microsoft Proxy Client, permettant de réaliser cette opération.
4.5 Les dangers
Confidentialité: Etant donné que vous demandez toutes vos pages au proxy, celui-ci peut savoir tous les sites que vous avez visité.
Mots de passe: Certains sites Web nécessitent des mots de passe. Comme vous passez par le proxy, le proxy connaîtra vos mots de passe (sauf si vous utilisez HTTPS/SSL).
Modifications: Le proxy vous fournit les pages, mais il est également possible qu’il les modifie à la volée avant de vous les donner (cela reste rare, mais possible !).
Censure: Certains proxy peuvent être configurés pour censurer des sites.
Il faut donc avoir confiance en l’administrateur du proxy. A vous de voir si vous voulez faire confiance au serveur proxy de votre fournisseur d’accès. Pour ceux des entreprises… c’est à voir ! Les spécialistes estiment que 70% des entreprises américaines examinent les accès des employés aux proxy.
Malgré tout, je vous recommande de désactiver – si vous le pouvez – le proxy quand vous devez accéder à des sites nécessitant des mots de passe.
4.6 Autre danger : les proxy transparents
En principe, vous indiquez volontairement que vous voulez utiliser un proxy.
Certains fournisseurs d’accès (comme Wanadoo ou AOL, dans certains cas), regardent quels protocoles vous utilisez et détournent sans vous le dire les requêtes HTTP vers leurs serveurs proxy.

Fig2. Connections qui passe par un proxy transparents.
Certains fournisseurs détournent les requêtes http sur leurs serveurs proxy sans vous le dire.
4.6.1 Pourquoi font-ils cela ?
- Cela permet d’effectuer des statistiques très précises sur les habitudes de navigation des internautes, et ce genre d’information se vend très bien aux sociétés de marketting.
- Cela permet d’économiser de la bande passante pour réduire la quantité de données reçues d’Internet.
- Il est également arrivé chez un fournisseur (AOL) que le proxy-cache recompresse les images avec une qualité moindre pour gagner de la place. Résultat: tous les sites consultés devennaient hideux (images de très mauvaise qualité).
4.6.2 Comment détecter un proxy transparent ?
En principe, quand vous vous connectez sur un site Web sans proxy, celui-ci doit voir votre adresse IP (ou celle de votre passerelle).
Il suffit de comparer votre adresse IP avec celle vue par le serveur Web. Désactivez le proxy dans votre navigateur, puis essayez par exemple un des sites suivants:
- http://cgisource.com/cgi-bin/env.cgi
- http://cpcug.org/scripts/env.cgi
- http://tools.blueyonder.co.uk/cgi-bin/env.cgi
Si vous ne passez pas par une passerelle, comparez le champ REMOTE_ADDR avec votre adresse IP. Si elles sont différentes, alors c’est que votre fournisseur d’accès utilise probablement un proxy transparent ! (ou bien que vous passez par une passerelle/pare-feu).
Je vous recommande de le sermoner votre fournisseur d’accès et d’exiger la suppression du proxy transparent.
Changez de fournisseur d’accès si ce dernier refuse !
(Pour connaître votre adresse IP, lancez winipcfg.exe sous Windows 95/98/ME, ou ipconfig.exe sous Windows NT/2000/XP).
4.7 Où trouver des serveurs proxy ?
Votre fournisseur d’accès possède très certainement des proxy à votre disposition pour accélérer votre navigation sur Internet. Regardez la documentation que vous a fourni votre fournisseur d’accès, ou demandez-leur. Ils se feront un plaisir de vous donner l’adresse.
4.8 Comment améliorer l’anonymat ?
Il faut filtrer le maximum d’information.
Si vous n’avez pas accès à des proxy anonymes, vous pouvez quand même utiliser des logiciels pour filtrer la plupart des informations (type de navigateur, etc.).
Je vous recommande Proxomitron. Il est gratuit et peut filtrer à la demande ces informations.
Vous avez également la possibilité de passer par des services spécialisés commehttp://www.anonymizer.com , http://megaproxy.com ou http://surfola.com. Certains services ne nécessitent pas reconfigurer le proxy, mais s’utilisent en se connectant directement dessus avec votre navigateur. Certains services sont payant, d’autres gratuits.
Le routage et les routeurs.
5.1 Le routage
Le routage est assuré par des équipements dites routeurs.
Les routeurs ne mettent en œuvre que les trois premières couches du modèle OSI. Ils dirigent les paquets vers leur destination. Ces équipements n’analysent généralement que l’entête des paquets IP. Ils disposent d’une table de routage indiquant vers quel routeur devra être transmis en fonction de l’@ IP destination comprise dans entête du paquet traité.

Fig2. Schéma descriptif du routage
5.2 Le Routeur.
Un routeur est un matériel de communication de réseau informatique destiné au routage. Son travail est de limiter les domaines de diffusion et de déterminer le prochain nœud du réseau auquel un paquet de données doit être envoyé, afin que ce dernier atteigne sa destination finale le plus rapidement possible. Ce processus nommé routage intervient à la couche 3 (couche réseau) dumodèle OSI.
Il ne doit pas être confondu avec un pont (couche 2), une passerelle (couche 4 à couche 7), ou unpare-feu.
5.3 B-routeurs.
Un B-Routeur (en anglais b-routeur, pour bridge-routeur) est un élément hybride associant les fonctionnalités d’un routeur et celles d’un pont. Ainsi, ce type de matériel permet de transférer d’un réseau à un autre les protocoles non routables et de router les autres. Plus exactement, le B-routeur agit en priorité comme un pont et route les paquets si cela n’est pas possible.
Un B-routeur peut donc dans certaines architectures être plus économique et plus compact qu’un routeur et un pont.
5.4 Précisions.
- Le routage est aujourd’hui souvent associé au protocole de communication IPv4, alors que la migration vers IPv6 fait également intervenir le routage d’IPv6. D’autres protocoles moins populaires existent, et sont routables.
- Les routeurs originaux des années 1960 étaient simplement des ordinateurs ordinaires, appelés « passerelles » (gateway), d’où le « G » qui apparaît dans de nombreux acronymes associés.
- Même si les ordinateurs ordinaires peuvent être utilisés pour faire le routage, les routeurs modernes sont plus souvent des ordinateurs très spécialisés, habituellement avec du matérielsupplémentaire pour accélérer des fonctions, comme le transfert (acheminement) de paquets, cependant, certains de ces routeurs spécialisés ne seraient pas compatible IPv6.
- D’autres différences par rapport à un ordinateur classique contribuent à améliorer la disponibilité et les performances, comme l’absence de stockage magnétique.
- Les routeurs actuels jouent donc pour les données un rôle proche de celui des commutateurs téléphoniques pour la voix. Certaines fonctions de ces derniers sont d’ailleurs de plus en plus reprises par les routeurs dans la convergence appelée voix ou téléphonie sur IP (VoIP, ToIP).
- Un routeur doit être connecté à au moins deux réseaux informatiques pour être utile, sinon il n’aura rien à router. L’appareil crée ou maintient une table, appelée table de routage, qui contient les meilleures routes vers d’autres réseaux via les métriques associées à ces routes. Voir l’article sur le routage pour plus de détails sur le fonctionnement de ce processus.
- Un routeur est un boîtier regroupant une carte mère, un microprocesseur et les ressources réseaux nécessaires (WiFi, Ethernet…). Il s’agit donc d’un ordinateur minimal dédié, dont le système d’exploitation est d’ailleurs souvent un dérivé allégé de Linux. De même, tout ordinateur disposant des interfaces adéquates (au minimum deux, souvent Ethernet) peut faire office de routeur s’il est correctement configuré (certaines distributions Linux minimales sont spécialisées dans cette fonction).
La fonction de routage consiste à traiter les adresses IP en fonction de leur adresse réseau définie par le masque de sous-réseaux (par défaut ou personnalisé) et à les diriger en fonction de l’algorithme de routage et de sa table de routage ( celle ci contient la correspondance des adresses réseau avec les numéros de port physique du routeur ou sont connectés les autres réseaux).
5.5 Fabricants de routeurs.
Routeurs « Physique » | Routeurs « logiciels » |
Les principaux fabriquants de routeur sont : | Avec un logiciel adapté et au moins deux cartes réseaux, on peut facilement transformer un PC ordinaire (même d’un modèle ancien) en un routeur. La plupart des systèmes d’exploitation basés sur UNIX (par exemple Linux ou FreeBSD) dispose des logiciels nécessaires au routage. citons quelques projets:
|
6. CISCO PIX FIREWALL.
6.1 Introduction.
La gamme de serveurs de sécurité dédiés Cisco PIX®, leader de son marché, fournit des services intégrés de sécurité de réseau de catégorie entreprise – pare-feu à inspection d’état, inspection des protocoles et des applications, établissement de réseaux privés virtuels (VPN), protection en ligne contre les intrusions, sécurité riche multimédia et VOIP, etc. – sous la forme de solutions économiques et faciles à déployer.
La gamme de serveurs de sécurité Cisco PIX s’étend des pare-feu de bureau compacts » plug-and-play » pour petits bureaux jusqu’aux pare-feu gigabit de catégorie opérateur télécom pour les entreprises les plus exigeantes et les environnements de fournisseurs de services. Chaque produit apporte aux environnements de réseau, quelle que soit leur taille, une protection robuste, de hautes performances et une grande fiabilité.
6.2 Caractéristiques du pare-feu Cisco PIX 501.
Dans cette partie, nous ne présenterons que le PIX 501, conçu pour les « petits » bureaux. Cinq autres modèles existent : 506, 515, 520, 525 et 535.

Fig2. L’interface Ethernet du Pare–feu Cisco PIX 501.

Fig2. L’interface de la console du Pare–feu Cisco PIX 501.
6.3 Caractéristiques matérielles.
Le Cisco PIX 501 est équipé d’un processeur AMD SC520 cadencé à 133 Mhz.
Il dispose de 16 Mo de mémoire vive SDRAM et d’une mémoire flash de 8 Mo.
Au niveau des interfaces de connexions, le PIX 501 possède 1 port Ethernet 10Base-T pour la connexion externe et un commutateur 10/100 Mb de 4 ports pour le réseau interne.
Un port console est également présent pour la configuration.
| Fonctions | PIX501 | PIX 506E | PIX 515E | PIX 525 | PIX 535 |
| Processeur | 133 Mhz | 300 Mhz | 433 Mhz | 600 Mhz | 1,0 Ghz |
| RAM (MB) | 16 Mo | 32 Mo | 32 ou 64 Mo | 128 ou 256 Mo | 512 Mo ou 1 Go |
| Mémoire Flash | 8 Mo | 8 Mo | 16 Mo | 16 Mo | 16 Mo |
| Emplacements PCI | Aucun | Aucun | 2 | 3 | 9 |
| Interfaces fixes (matérielles) | Commutateur 10/100 à 4 ports (internes), un port Ethernet 10Base-T (externe) | Deux ports Ethernet 10Base-T | Deux ports Fast Ethernet 10/100. | Deux ports Fast Ethernet 10/100. | Aucune |
| Nombre maximal d’interfaces (matérielles et virtuelles) | Commutateur 10/100 à 4 ports (internes), un port Ethernet 10Base-T (externe) | Deux ports Ethernet 10Base-T | Six ports Fast Ethernet (FE) 10/100 ou 8 VLAN | Huit ports FE 10/100 ou GE ou 10 VLAN | Dix ports FE 10/100 ou GE ou 24 VLAN |
| Option carte VAC+ (VPN Accelerator Card+) | Non | Non | Oui, intégrée sur certains modèles | Oui, intégrée sur certains modèles | Oui, intégrée sur certains modèles |
| Support de reprise | Non | Non | Oui, sur les modèles UR/FO seulement | Oui, sur les modèles UR/FO seulement | Oui, sur les modèles UR/FO seulement |
| Dimensions | Ordinateur de bureau | Ordinateur de bureau | 1 unité de rack (RU) | 2 RU | 3 RU |
6.4 Caractéristiques fonctionnelles.
Le PIX est un pare-feu à inspection d’état, il se base donc sur les couches 3 et 4 du modèle OSI et peut assurer le suivi des échanges et utilise l’ASA (Adaptive Security Algorithm) pour ce filtrage dynamique. Si les paquets d’une communication sont acceptés alors les paquets suivants de cette communication seront acceptés implicitement.
De plus l’ASA permet d’affecter des niveaux de sécurité à vos interfaces. Ainsi un niveau égal à 0 équivaut à un réseau non sécurisé (internet), et un niveau égal à 100, à un réseau digne de confiance (réseau interne). Pour les PIX équipés de plus de 2 interfaces, des niveaux entre 1 et 99 peuvent être assignés : DMZ et autres réseaux plus vulnérables que le réseau local.
Il peut aussi contrôler l’accès de différentes applications, services et protocoles et protège votre réseau contre les attaques connues et courantes.
Ce pare-feu gère également le VPN (IKE et IPSec). On peut ainsi créer des tunnels VPN entre sites.
Le PIX peut aussi faire office de serveur DHCP pour les équipements connectés au réseau interne et grâce au NAT, permet à ces « clients » de se connecter à Internet avec une même adresse IP publique.
6.5 Principe de fonctionnement du routeur filtrant.
1) Stocker les règles de filtrage sur chaque port physique du routeur.
2) Analyser l’en-tête du datagramme.
3) Appliquer les règles de filtrage aux paquets reçus.
4) Si une règle indique que le paquet doit être bloqué, celui-ci est rejeté.
5) Si une règle indique que le paquet doit être accepté, celui-ci est routé conformément à sa table de routage.
6) Si aucune règle ne s’applique, ce sont des règles par défaut (configurables par l’administrateur) qui seront appliquées. Ainsi, si dans un tel cas on rejette les paquets, on peut bloquer tout trafic non explicitement permis
Remarque .
- L’ordre des règles est très important. Ainsi dans la liste ci-dessus, si la règle 3 avait été mise en premier, tous les paquets auraient été rejetés par le filtre.
- Si les règles définies sont insuffisantes ou mal conçues, le risque d’intrusion est grand.
- Le filtrage sur les drapeaux TCP s’effectue le plus souvent sur les drapeaux ACK et SYN( exemple : on contrôle le nombre de message SYN émis par une même source).
6.6 Avantages.
ü gain de temps pour la mise en place.
ü coût généralement faible.
ü performances assez bonnes.
ü transparence aux utilisateurs et aux applications.
6.7 Limitation.
ü L’élaboration de règles de filtrage peut être une opération pénible à partir du moment où l’administrateur réseau doit avoir une compréhension détaillée des différents services Internet et du format des en-têtes des paquets. Si des règles complexes de filtrage doivent être mises en place, c’est un processus long, lourd et difficile à faire évoluer et à comprendre. De plus, une mauvaise configuration peut conduire le site à rester vulnérable à certaines attaques.
ü Le pare-feu filtre de paquets ne protège pas contre les applications du type Cheval de Troie car il n’analyse pas le contenu des paquets. Il est donc possible de tenter une attaque par tunneling de protocole, c’est à dire passer par les protocoles autorisés pour en atteindre d’autres interdits.
ü Plus le nombre de règles à appliquer est grand, plus les performances du pare-feu diminuent, diminuant d’autant les performances de tout le système. On doit alors faire ici un choix parfois crucial entre performance et sécurité.
ü Le pare-feu filtrant n’est pas capable de comprendre le contexte du service qu’il rend : il ne peut par exemple pas bloquer l’importation de mail concernant certains sujets.
6.8 Configuration de base.
La configuration du PIX peut s’effectuer par le biais de commandes entrées manuellement par l’administrateur ou via une interface web : le Pix Device Manager (PDM).
Nous aborderons ici les commandes essentielles et donc, l’interface en ligne de commande (CLI).
6.8.1 Modes de commandes.
A l’instar des routeurs, il existe plusieurs niveaux d’accès administratifs :
– Mode utilisateur : mode par défaut, on peut consulter certaines informations sur le pare-feu mais sans pouvoir effectuer de modifications.
– Mode privilégié : permet de procédér à la configuration de base du pare-feu et de visualiser son état.
– Mode de configuration globale : comme son nom l’indique, permet de configurer les paramètres ayant une portée globale.
Les commandes accessibles depuis un mode le sont aussi dans le mode supérieur.
Afin d’identifier ces différents modes, il suffit de faire attention à l’invite de commandes.
Ainsi en mode utilisateur, on aura : hostname>
En mode privilégié : hostname#
Et en mode de configuration globale : hostname(config)#
Pour passer d’un mode à l’autre il faut utiliser les commandes suivantes :
– enable pour passer du mode utilisateur à privilégié et disable ou exit pour l’inverse.
– configure terminal pour passer du mode privilégié à configuration globale et exit pour l’inverse.
Maintenant, nous pouvons commencer à configurer le PIX.