Ever want to list all the Linux commands (including bash shell aliases and functions) you could run on the server / workstation? Look now further. Try compgen command.
compgen is bash built-in command and it will show all available commands, aliases, and functions for you. The syntax is:
In this tutorial, I’ll show you the steps to create a simple failover cluster on Ubuntu using CARP. To make the things meaningful,we’ll create the cluster for Apache service but you can use it for any other service, which relay on IP.
Scenario:
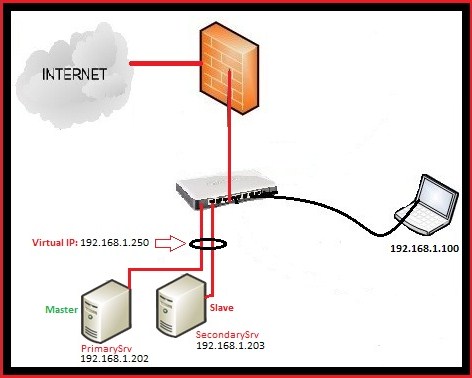
Here is my Setup:
PrimarySrv: This is the main server, where I configured the apache and which act as Master (IP: 192.168.1.202) SecondarySrv: 2nd Apache Server where I configured the apache exactly like on PrimarySrv (IP : 192.168.1.203) 192.168.1.250 : Virtual IP address,created using Ucarp.
Ucarp is really simple, it works like this,when the PrimarySrv is up,it will assign the virtual IP 192.168.1.250 to it, in case that PrimarySrv is down then it will assign virtual IP to the SeconadrySrv and when the PrimarySrv will come online, it will assign the virtual IP once again to it.
Do you need a simple open source cross-platform command line tool that converts web pages and HTML to a PDF file? Look no further, try wkhtmltopdf.
From the project home page:
Simple shell utility to convert html to pdf using the webkit rendering engine, and qt. Searching the web, I have found several command line tools that allow you to convert a HTML-document to a PDF-document, however they all seem to use their own, and rather incomplete rendering engine, resulting in poor quality. Recently QT 4.4 was released with a WebKit widget (WebKit is the engine of Apples Safari, which is a fork of the KDE KHtml), and making a good tool became very easy.
Software features
Cross platform.
Open source.
Convert any web pages into PDF documents using webkit.
You can add headers and footers.
TOC generation.
Batch mode conversions.
Can run on Linux server with an XServer (the X11 client libs must be installed).
Can be directly used by PHP or Python via bindings to libwkhtmltox.
A note about Debian / Ubuntu Linux user
You can install wkhtmltopdf using apt-get command: $ sudo apt-get install wkhtmltopdf $ sudo ln -s /usr/bin/wkhtmltopdf /usr/local/bin/html2pdf
Sample outputs:
[sudo] password for vivek:
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
wkhtmltopdf
0 upgraded, 1 newly installed, 0 to remove and 10 not upgraded.
Need to get 116 kB of archives.
After this operation, 303 kB of additional disk space will be used.
Get:1 http://debian.osuosl.org/debian/ squeeze/main wkhtmltopdf amd64 0.9.9-1 [116 kB]
Fetched 116 kB in 2s (49.4 kB/s)
Selecting previously deselected package wkhtmltopdf.
(Reading database ... 274164 files and directories currently installed.)
Unpacking wkhtmltopdf (from .../wkhtmltopdf_0.9.9-1_amd64.deb) ...
Processing triggers for man-db ...
Setting up wkhtmltopdf (0.9.9-1) ...
Source: munin-monitoring.org There are a number of situations where you’d like to run munin-node on hosts not directly available to the Munin server. This article describes a few scenarios and different alternatives to set up monitoring. Monitoring hosts behind a non-routing server.
In this scenario, a *nix server sits between the Munin server and one or more Munin nodes. The server in-between reaches both the Munin server and the Munin node, but the Munin server does not reach the Munin node or vice versa.
To enable for Munin monitoring, there are several approaches, but mainly either using SSH tunneling or “bouncing” via the in-between server.
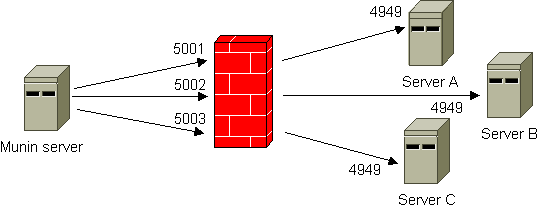
SSH tunneling
The illustration below shows the principle. By using SSH tunneling only one SSH connection is required, even if you need to reach several hosts on “the other side”. The Munin server listens to different ports on the localhost interface. A configuration example is included. Note that there is also a FAQ entry on using SSH that contains very useful information.
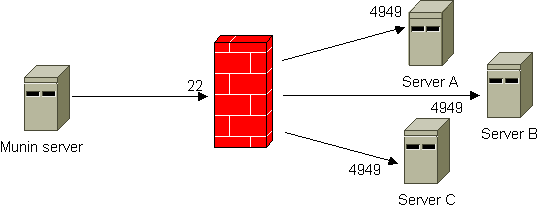
Bouncing
This workaround uses netcat and inetd/xinetd to forward the queries from the Munin server. All incoming connections to defined ports are automatically forwarded to the Munin node using netcat.