Voyage au centre du noyau: Traffic Control, la QoS
Gérer la QoS.
On peut aujourd’hui largement envisager d’héberger un ou plusieurs services sur son serveur à domicile, et des mouvements comme auto-hebergement.fr l’on bien illustré. Reste le problème de la bande passante en upload, qui bien que largement suffisante pour héberger des serveurs web, email, jabber ou autre, reste à utiliser intelligemment.
Linux fournit cette intelligence, sous forme d’un scheduler de paquets nommé Traffic Control (TC, pour les intimes), et l’objectif de cet article est de présenter cette technologie et sa mise en place dans un cas d’étude d’hébergement Web, DNS et même BitTorrent. Notons au passage que bon nombre de scripts et programmes existent pour simplifier la mise en place de la QoS (Quality of Service). Citons Wondershaper, Shorewall, ADSL-Optimizer par exemple. Cet article n’en parlera pas, car l’objectif est ici de faire mais aussi de comprendre comment ça marche sous le capot, et pour ça, il faut démonter le moteur et mettre les mains dans le cambouis.
1. Traffic Control, la QoS, les bases
Traffic Control travaille sur les paquets sortant du noyau. Il n’a pas, initialement, pour objectif de contrôler le trafic des paquets entrants. Cette portion de code du noyau se situe entre la couche IP et le pilote du matériel qui transmet sur le réseau. On est donc très bas dans les couches. En réalité, c’est Traffic Control qui est constamment en charge de transmettre au driver de la carte réseau le paquet à envoyer.

Cela signifie, en fait, que le module TC – le scheduler de paquet – est en permanence activé dans le noyau, même quand vous ne pensez pas l’utiliser. Par défaut, ce scheduler maintient une queue (prononcer kiou, une file d’attente) similaire à FIFO dans laquelle le premier paquet entré est donc le premier sortit.
La base de TC est la Queuing Discipline (qdisc) qui représente la politique de scheduling appliquée à une queue. Il existe différentes qdisc. Comme pour le scheduling processeur, on retrouve les méthodes FIFO, FIFO à plusieurs files, FIFO avec hash et round robin (SFQ). On a également un système Token Bucket Filter (TBF) qui attribue des jetons (tokens) à une qdisc pour en limiter le débit (pas de token = pas de transmission = on attend d’avoir un jeton disponible). Cette dernière politique a ensuite été étendue à un TBF hiérarchique, le HTB (Hierarchical Token Bucket). Les politiques que nous allons étudier ici sont TBF, qui pose les fondamentaux, SFQ et HTB. Nous allons également jeter un coup d’oeil à la politique par défaut, que, tout Monsieur Jourdain que nous sommes, nous utilisons sans le savoir: pfifo_fast.
1.1 Premier contact
Jean-Kevin est pressé, il n’a pas de temps à perdre, et tout de suite maintenant, il doit limiter la bande passante sortante de son serveur web à 200kbits par secondes (25ko/s). Au diable la théorie, on y reviendra plus tard, mettons tout de suite les mains dans le cambouis. La mécanique que nous allons mettre en place est simple. Nous allons utiliser une règle Netfilter pour marquer les paquets qui nous intéressent. Ensuite, nous allons fournir à TC une politique qui s’appliquera sur les paquets contenant la marque définie. C’est parti.
1.2 Netfilter MARK
Netfilter permet d’interagir directement avec la structure représentant un paquet dans le noyau. Cette structure, le sk_buff, possède un champ « __u32 nfmark » que l’on va renseigner et qui sera lu par le filtre de TC pour sélectionner la classe de destination du paquet. La règle iptables suivante va appliquer la marque ’80’ sur les paquets sortant (chaine OUTPUT) ayant pour port source le port 80:
# iptables -t mangle -A OUTPUT -o eth0 -p tcp --sport 80 -j MARK --set-mark 80
On peut vérifier que cette règle est bien appliquée aux paquets sortants en visualisant les statistiques de Netfilter.
# iptables -L OUTPUT -t mangle -v Chain OUTPUT (policy ACCEPT 74107 packets, 109M bytes) pkts bytes target prot opt in out source destination 73896 109M MARK tcp -- any eth0 anywhere anywhere tcp spt:www MARK xset 0x50/0xffffffff
1.3 Deux classes dans un arbre
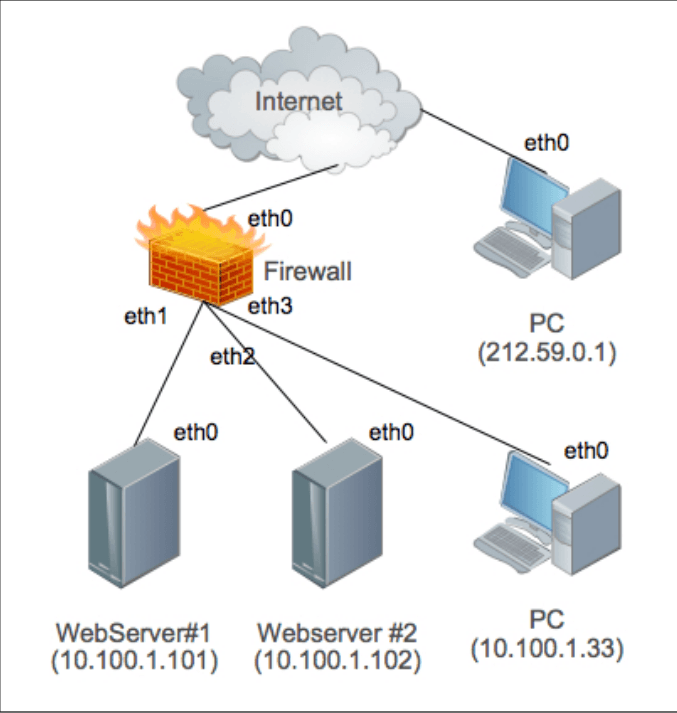
Le binaire /sbin/tc est compris dans le package iproute (sous Debian). Un simple aptitude suffit à l’installer, s’il ne l’est pas déjà. Nous allons créer un arbre dont la racine appliquera la politique HTB. Cet arbre va contenir deux classes: une pour notre trafic marqué, l’autre pour tout le reste et qui sera donc considérée par défaut.
# tc qdisc add dev eth0 root handle 1: htb default 20 # tc class add dev eth0 parent 1:0 classid 1:10 htb rate 200kbit ceil 200kbit prio 1 mtu 1500 # tc class add dev eth0 parent 1:0 classid 1:20 htb rate 1024kbit ceil 1024kbit prio 2 mtu 1500
Les deux classes filles sont raccrochés à la racine. Ces classes possèdent un débit garantie (rate) et un débit maximal opportuniste (ceil). Si la bande passante n’est pas utilisée, alors une classe pourra monter son débit jusqu’à la valeur de ceil. Sinon c’est la valeur de rate qui s’applique. Cela veut dire que la somme des valeurs de rate doit correspondre à la bande passante disponible. Dans le cas d’un upload ADSL classique chez un fournisseur correct, cela sera d’environ 1024kbits (dans le meilleur des cas, éloignement du DSLAM, etc…).
Nous avons maintenant d’un côté un arbre de contrôle de trafic, et d’un autre côté du marquage de paquets. Il reste donc à relier les deux. Cela est fait avec les règles de filtrage de TC. Ces règles sont très simples. On dit à TC de prendre en charge (handle) les paquets portant la marque 80 et de les envoyer (fw flowid) à la classe correspondante. Un point important toutefois, un filtre doit être rattaché à la racine « root » de l’arbre. Sinon, il n’est pas pris en compte.
# tc filter add dev eth0 parent 1:0 protocol ip prio 1 handle 80 fw flowid 1:10
Faisons maintenant le test avec NetCat, on ouvre un port en écoute qui renvoi des zéro. C’est basique et parfait pour tester notre politique. On lance donc :
# nc -l -p 80 < /dev/zero
Et sur une autre machine, on lance un telnet vers le port 80 de la machine en écoute. L’outil iptraf permet de visualiser la connexion en cours et, surtout, son débit (voir figure 2).

Comme on le voit dans l’encadré rouge, en bas à droite, le débit de la connexion est de 199,20kbps. On s’approche de beaucoup des 200kbps, la précision dépendant quelques paramètres que nous allons étudier. Si l’on teste une connexion du même type sur un autre port, on verra un débit limité à 1024kbps, ce qui correspond au débit de la classe par défaut qui s’applique à tous les paquets non marqués.

{kind=link}
{kind=link}