Mass-blocking IP addresses with ipset

Using ipset to block many IP addresses
I was sponsoring an upload of ipset to Debian the other day. This reminded me of ipset, a very cool program as I am going to show. It makes administering related netfilter (that is: firewall) rules easy along with a good performance. This is achieved by changing how rules match in iptables. Traditionally, an iptables rule matches a single network identity, for example a single IP address or a single network only. With ipsets you can operate on a bunch of (otherwise unrelated) addresses at once easily. If you happen to need bulk actions in your firewall, for example you want to blacklist a long list of IP addresses at once, you will love IP sets. I promise.
Drawbacks of netfilter
IP sets do exist for a longer time, however they made it into the upstream Linux kernel as of version 2.6.39. That means Debian Wheezy will support it as is; for Debian Squeeze you can either use a backported kernel or compile yourself the module shipped in the ipset-source package. In any case you additionally need the command line utilities named ipset. Thus, install that package before you can start. Having that said, Squeeze users should note the ipset syntax I am demonstrating below slightly differs from the syntax supported by the Squeeze utilities. The big picture remains the same, though.
IP utils do not conflict with iptables, but extend it in a useful way. You can combine both as you like. In fact, you still need iptables to turn IP sets into something really useful. Nonetheless you will be hitting iptables‘ limitation soon if you exceed a certain number of rules. You can combine as many conditions within a filter rule as you like, however you can only specify a single pattern for each condition. You figure, this does not scale very well if a pattern to match against does not follow a very tight definition such as a CIDR pattern.
This means you can happily filter whole network blocks such as 192.168.0.0/24 (which translates to 255 hosts) in iptables, but there is no way to specify a particular not specially connected set of IP addresses within this range if it cannot be expressed with a CIDR prefix. For example, there is no way to block, say, 192.168.0.5, 192.168.0.100 and 192.168.0.220 in a single statement only. You really need to declare three rules which only differ by the IP address. Pretend, you want to prevent these three addresses from accessing your host. You would probably do something like this:
iptables -A INPUT -s 192.168.0.5 -p TCP -j REJECT iptables -A INPUT -s 192.168.0.100 -p TCP -j REJECT iptables -A INPUT -s 192.168.0.220 -p TCP -j REJECT
Alternatively you could do
iptables -A INPUT -s 192.168.0.0/24 -p TCP -j REJECT
but this would block 251 unrelated hosts, too. Not a good deal I’d say. Now, while the former alternative is annoying, what’s the problem with it? The problem is: It does not scale. Netfilter rules work like a fall-through trapdoor. This means whenever a packet enters the system, it passes through several chains and in each of these chains, netfilter checks all rules until either one rule matches or there are no rules left. In the latter case the default action applies. In netfilter terminology a chain determines when an interception to the regular packet flow occurs. In the example above the specified chain is INPUT, which applies to any incoming packet.
In the end this means every single packet which is sent to your host needs to be checked whether it matches the patterns specified in every rule of yours. And believe me, in a server setup, there are lots of packets flowing to your machine. Consider for example a single HTTP requests, which requires at very least four packets sent from a client machine to your web server. Thus, each of these packets is passing through your rules in your INPUT chain as a bare minimum, before it is eventually accepted or discarded.
This requires a substantial computing overhead for every rule you are adding to your system. This isn’t so much of a problem if you haven’t many rules (for some values of “many” as I am going to show). However, you may end up in a situation where you end up with a large rule set. For example, if you suffer from a DDoS attack, you may be tempted to block drone clients in your firewall (German; Apache2. Likewise: for Lighttpd). In such a situation you will need to add thousands of rules easily.
Being under attack, the performance of your server is poor already. However, by adding many rules to your firewall you are actually further increasing computing overhead for every request significantly. To illustrate my point, I’ve made some benchmarks. Below you find the response times of a HTTP web server while doing sequential requests for a single file of 10 KiB in size. I am explaining my measurement method in detail further below. For now, look the graph. It shows the average response time of an Apache 2 web server, divided into four parts:
- connect time: this is the time passed by until the server completed the initial TCP handshake
- send time: this is the time passed by which I needed to reliably send a HTTP request over the established TCP connection reliably (that means: one packet sent and waiting for acknowledged by the server)
- first byte: this is time passed by until the server sent the first byte from the corresponding HTTP response
- response complete: this is time passed by until the server sent all of the remaining bytes of the corresponding HTTP response (remaining HTTP header + 10 KiB of payload)
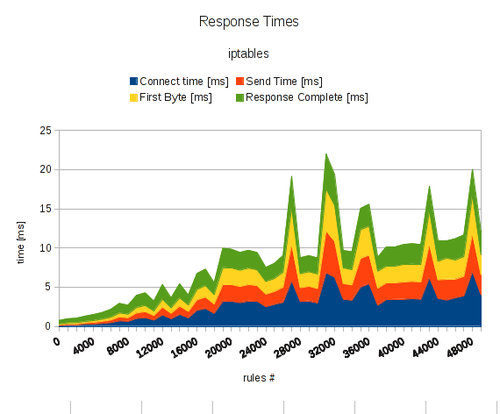
Summing up these delays (roughly) equals to the complete response time of a typical HTTP request. In the plot below I am showing the average of thousand requests for each measure point. In between every step I increased the number of netfilter rules by 1000. I started with no rules at all and slowly increased the number of rules up to 50000, while the request itself remained unchanged.
As you can see, the response slows down drastically. Starting with a delay of 0.76 ms when benchmarking without firewall, I ended up with 12 ms in the end with the average over the whole set being 8.59 ms. This includes other delays such as network, protocol overhead, but these were considered constant for the time of my measurements. It can be seen, the response time delay linearly grows with an ascending number of rules. This is feasible as the computation delay linearly grows with every rule added to the table. Having that said, I have no answer for the spikes in between. I’ll need to further investigate this. Since the table overhead caused a substantial computation overhead I suspect this could be because of process piling. This is a summary table of delays I measured:
| Rules # | Connect time [ms] | Send Time [ms] | First Byte [ms] | Response Complete [ms] | Complete Request [ms] |
|---|---|---|---|---|---|
| 0 | 0,11 | 0,09 | 0,09 | 0,47 | 0,76 |
| 1000 | 0,17 | 0,14 | 0,14 | 0,52 | 0,98 |
| 5000 | 0,37 | 0,27 | 0,27 | 0,85 | 1,77 |
| 10000 | 1,11 | 0,78 | 0,78 | 1,62 | 4,28 |
| 15000 | 1,08 | 0,82 | 0,82 | 1,28 | 4 |
| 20000 | 3,18 | 2,13 | 2,13 | 2,41 | 9,85 |
| 25000 | 2,8 | 1,65 | 1,65 | 1,93 | 8,04 |
| 30000 | 2,98 | 1,85 | 1,85 | 2,06 | 8,75 |
| 35000 | 5,01 | 3,67 | 3,67 | 2,71 | 15,05 |
| 40000 | 3,46 | 2,2 | 2,2 | 2,58 | 10,44 |
| 45000 | 3,35 | 2,68 | 2,68 | 2,17 | 10,89 |
| 50000 | 4,01 | 2,55 | 2,55 | 2,95 | 12,06 |
Using ipsets
The use of IP sets is surprisingly easy. Basically you only need to name set name with an arbitrary name, pick its type and throw a bunch of entries into it. Finally it needs to be referenced by an iptables and you’re done. Despite its name, ipset supports more than just IP addresses. You can store almost every common network identifier in such a set. For example ipset supports storing of TCP ports, MAC addresses, IP networks, simple IP addresses, network interfaces and most combinations thereof, too. It’s important to pick the right set for your purpose as the resulting filter pattern and computation speed vastly depends on the indexed key to be used.
In my example below I am using IP hashes since all I want is to store a bunch of IP addresses in my set. Applying IP sets in your network is realized using these simple commands:
ipset create blacklist hash:ip hashsize 4096
iptables -I INPUT -m set --match-set blacklist src -p TCP \
--destination-port 80 -j REJECTThe first line creates a new IP set (which can be deleted again with “ipset destroy” if you want to) named blacklist of the type hash:ip and a hash index size of 4 KiB. See the ipset(8) man page to lookup further options and types. Once the set was declared, it can be loaded into netfilter by using iptables. You can make use of iptables as usual, it’s just that every rule does not apply to a single source address (or a single network) anymore, but to any address in the whole set. The rule disassembled looks like this:
- “
-I INPUT” means the rule is applied to the INPUT chain. Within the netfilter state machine, packets pass the INPUT chain if they are destined to the host itself before they are handed over to a local socket. Other chains recognized by netfilter are PREROUTING, POSTROUTING, FORWARD and OUTPUT. - “
-m set --match-set blacklist src” hooks up the IP set. The -m switch enables a particular matching module, in this case it’s the IP set extension. Thereafter you only need to declare which set you want to associate with this rule (“blacklist“) and whether this should applied to source or destination IPs (“src“) - “
-p TCP --destination-port 80” further requires that the packet must be send over the TCP protocol to the destination port 80 (HTTP) to match - If all these conditions are fulfilled, the to REJECT the packet applies, which causes the Linux kernel to send a TCP reset to the source
Now, that the rule is there: Which addresses actually belong to a set? The answer is: All addresses which you add to it. This is effectuated by a simple series of self explaining commands:
ipset add blacklist 192.168.0.5 ipset add blacklist 192.168.0.100 ipset add blacklist 192.168.0.220
You can look-up the result by using ipset list:
$ ipset list Name: blacklist Type: hash:ip Header: family inet hashsize 4096 maxelem 65536 Size in memory: 65704 References: 1 Members: 192.168.0.100 192.168.0.220 192.168.0.5
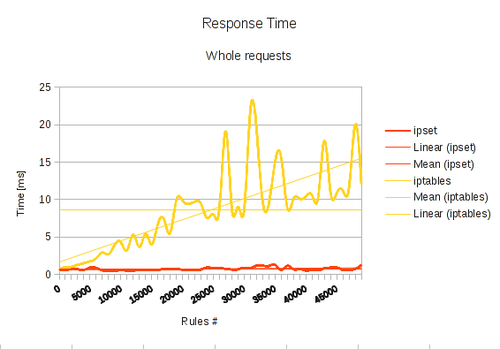
Let’s look at benchmarks again to see how ipset performs when compared to iptables. Hence, I repeated the same procedure again, this time using ipset instead of iptables to block up to 50000 IPs with a single iptables rule containing all IP addresses in a set.

Impressive. Isn’t it? Whether I had a single rule in chain or the whole bucket size of 50000 IPs – the response delay remained nearly constant. Pay attention at the different scale on the Y-axis when compared to the corresponding iptables plot. Whether I used a single IP or 5000 IPs in the set, I never peaked higher than 1.4 ms per request. Moreover, the mean response time was 0.76 ms. This makes the use of ipsets for the same task roughly 11 times faster than iptables. The delay is nearly and not depending of the actual size of the working set – in contrast to a linear growth of the iptables approach. This is not such a big surprise as that’s how hashing algorithms do work. They share a common principle to index elements by using a constant time hashing function. Again a summary table of measured response delays follows below:
| Rules | Connect time [ms] | Send Time [ms] | First Byte [ms] | Response Complete [ms] | Complete Request [ms] |
| 0 | 0,08 | 0,08 | 0,08 | 0,39 | 0,63 |
| 1000 | 0,08 | 0,07 | 0,07 | 0,35 | 0,57 |
| 5000 | 0,13 | 0,13 | 0,13 | 0,54 | 0,93 |
| 10000 | 0,08 | 0,07 | 0,07 | 0,35 | 0,58 |
| 15000 | 0,08 | 0,08 | 0,08 | 0,36 | 0,61 |
| 20000 | 0,09 | 0,09 | 0,09 | 0,39 | 0,65 |
| 25000 | 0,11 | 0,11 | 0,11 | 0,52 | 0,84 |
| 30000 | 0,12 | 0,11 | 0,11 | 0,56 | 0,91 |
| 35000 | 0,18 | 0,18 | 0,18 | 0,76 | 1,29 |
| 40000 | 0,07 | 0,07 | 0,07 | 0,32 | 0,54 |
| 45000 | 0,13 | 0,13 | 0,13 | 0,56 | 0,95 |
| 50000 | 0,18 | 0,18 | 0,18 | 0,74 | 1,28 |
The Measurement Method
I was setting up an Apache 2 web server to serve a static chunk of random data, 10 KiB large. The chunk was generated by using dd. I didn’t specially configure Apache, in particular I didn’t change the Debian Sid default configuration. This does not perform very well on busy systems with lots of concurrency, but that’s irrelevant for my use case. I was doing sequential requests only to make sure I’m really testing I/O network performance and not concurrency bottlenecks.
Moreover, all benchmarks I did were done using the local loopback interface. That means no real signaling delay is measurable either, as no packet left my machine for real. Hence I was really measuring performance of the software stack. The way I measured can be summarized as follows: I repeatedly fired HTTP requests to the local web server and measured the response time, further divided in the four phases outlined above. I used HTTP 1.0 only and did not make use of the connection keep-alive feature. I used the plain socket interface, but I realize there is nonetheless a certain measurement error as I was simply collecting the time spent for certain socket operations. That said, this measurement error is constant among all samples I did. I increased the number of IP addresses to be blocked by thousand for every iteration I did. I started without any IP address in the filter and successively increased the number to 50000 rules. To protect from statistical spikes I repeated the same request 1000 times for every iteration. I generated random IP addresses to fill the table but I made sure, no address would really match. Thus, every HTTP request was guaranteed to pass through the entire chain for each request. The Python source code to measure is available upon request.
Summary
It has been shown, the hash approach as implemented by ipset clearly beats traditional mass-rule-blocking. It extends netfilter in a very useful way by decreasing the average response time. In the average over all samples made, IP sets are over 11 times faster. To conclude, let me show you another plot, this time I compared the ipset and iptables approaches within the same graph. The yellow bar shows ipset delays, the red bar does so for iptables.
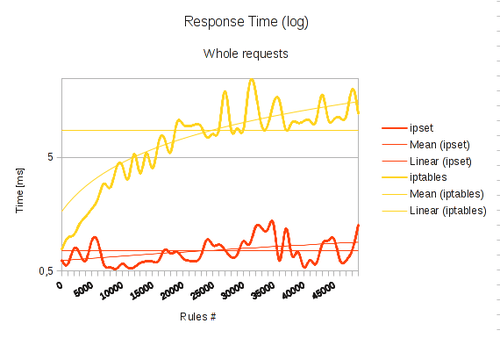
While ipset's delays remain on a low level during the whole test, iptables rules steadily grow. However, please note for most use cases using iptables is perfectly fine. There is no significant performance penalty for a pretty decent number of rules. You’re fine if you are roughly using less than 5000 rules – and that’s quite a lot already. There won’t be any firewall out there which comes close to this number for the daily use. In fact, you will only hit that limit if you are running a public facing server which is under heavy DDoS attack. In such a situation it makes perfect sense to drop all IP addresses which are attacking you (but make sure, they are not spoofed. You are wasting your time otherwise). Doing so you probably end up bulk loading lots of single IP addresses (which can’t be aggregated to block whole ISP ranges for example) to your firewall. In such a case use IP sets. You can see best why, if you look at another graph below. It shows the same information once again, this time with the Y-axis on a logarithmic scale.
Source: d(a)emonkeeper’s purgatory