Here’s how you can block traffic coming from an IP, list of IPs, full networks or even entire countries. This is done under a Debian 7 x86 server so adapt the commands to your distro of choice…
1 – Install ipset, for commands reference check http://ipset.netfilter.org
apt-getinstall ipset
2 – Setup your sets, sets are basically lists in which you’ll add all the IP or IP networks to it, in this case I’m creating a list to support IP Networks (x.x.x.x/yy form). If you need to create a set to support individual IPs use the hash:ip option.
#Create 3 lists, 2 to support networks and 1 to support single IP addresses
#hash:net = Networks
#hash:ip = single IPs
# Command is ipset -N setname [set options], but I'm using default
# options here
ipset-Nchina hash:net
ipset-Nsome-country hash:net
ipset-Nbadguys hash:ip
# Now we list the just created sets with:
ipset-L
When the Great Firewall of China starts hosing your server with unexpected and unrelated traffic, how do you deal with it?
Discovering a problem
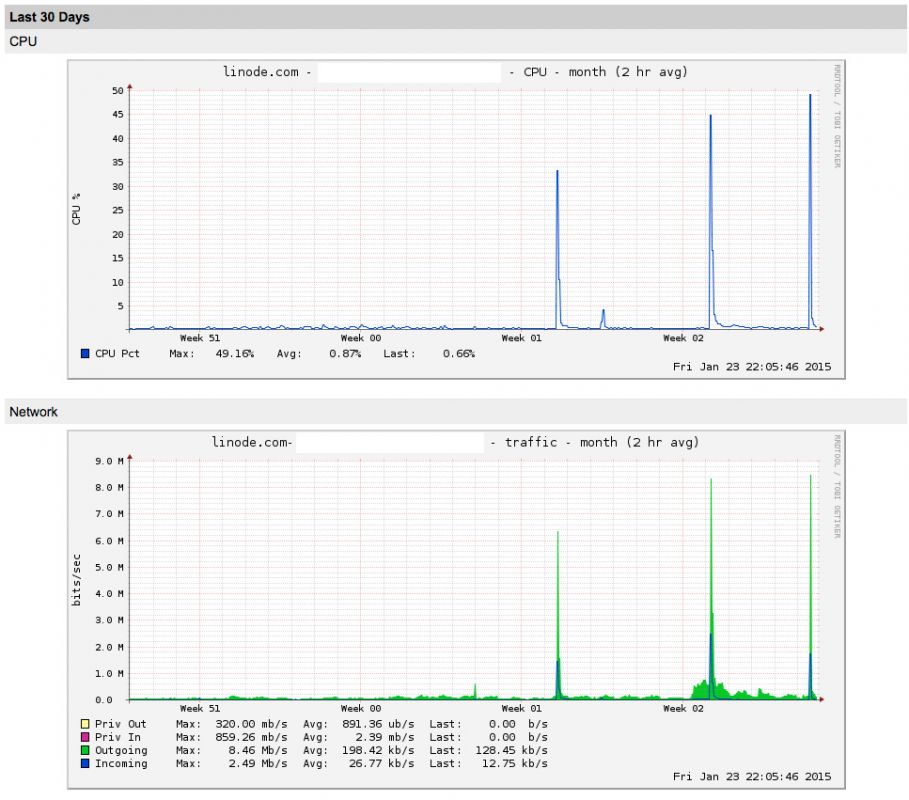
Three times in the last week I’ve had email reports from my Linode’s automatic warning system, informing me that the server had exceeded an average 8Mb/s output for a two hour period. Each time I logged on the traffic had gone right back down, and my website analytics never showed unusual traffic. By the third occurrence I wanted to get to the bottom of it, and I already had suspicions.
Those spikes are not normal.
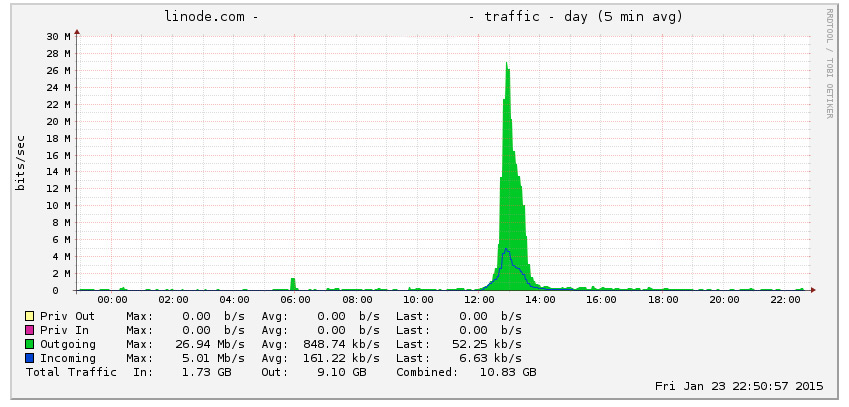
Earlier in the day I’d stumbled across Craig Hockenberry’s post Fear China, where he was seeing a similar (but larger) problem over a longer period than I was. I looked into my access logs… and discovered I did indeed have the same problem, though it looks like I caught it earlier., or it was less severe.
Being DDOS’d via the Great Firewall of China
Distributed Denial of Service attacks flood a server with pointless requests from many computers all at once.
My logs showed requests for services and URLs that had nothing to do with my server, including an awful lot of BitTorrent URLs. Checking the geolocation of the requesting IPs showed they were all inside China. As Craig’s post covered – it looks a lot like there’s a mis-configuration with China’s state controlled firewall, and people’s normal traffic is sometimes being sent to entirely the wrong servers.
I wondered how bad my server was getting hit, as it didn’t seem to be in the same league as Craig’s:
Almost 27Mb/s out is roughly 95 times greater than normal for that server – close to two orders of magnitude increase, and I didn’t like that – I could imagine this getting worse rapidly.
Blocking China
As Craig discusses, there’s really no option but to block everyone from China. Unfortunately for me, I wasn’t using ipfw as a firewall so I couldn’t follow his advice. Having finally figured out how to do this I thought I’d write a step-by-step guide assuming you’ve not got a firewall already set up.
I was sponsoring an upload of ipset to Debian the other day. This reminded me of ipset, a very cool program as I am going to show. It makes administering related netfilter (that is: firewall) rules easy along with a good performance. This is achieved by changing how rules match in iptables. Traditionally, an iptables rule matches a single network identity, for example a single IP address or a single network only. With ipsets you can operate on a bunch of (otherwise unrelated) addresses at once easily. If you happen to need bulk actions in your firewall, for example you want to blacklist a long list of IP addresses at once, you will love IP sets. I promise.
Drawbacks of netfilter
IP sets do exist for a longer time, however they made it into the upstream Linux kernel as of version 2.6.39. That means Debian Wheezy will support it as is; for Debian Squeeze you can either use a backported kernel or compile yourself the module shipped in the ipset-source package. In any case you additionally need the command line utilities named ipset. Thus, install that package before you can start. Having that said, Squeeze users should note the ipset syntax I am demonstrating below slightly differs from the syntax supported by the Squeeze utilities. The big picture remains the same, though.
IP utils do not conflict with iptables, but extend it in a useful way. You can combine both as you like. In fact, you still need iptables to turn IP sets into something really useful. Nonetheless you will be hitting iptables‘ limitation soon if you exceed a certain number of rules. You can combine as many conditions within a filter rule as you like, however you can only specify a single pattern for each condition. You figure, this does not scale very well if a pattern to match against does not follow a very tight definition such as a CIDR pattern.
This means you can happily filter whole network blocks such as 192.168.0.0/24 (which translates to 255 hosts) in iptables, but there is no way to specify a particular not specially connected set of IP addresses within this range if it cannot be expressed with a CIDR prefix. For example, there is no way to block, say, 192.168.0.5, 192.168.0.100 and 192.168.0.220 in a single statement only. You really need to declare three rules which only differ by the IP address. Pretend, you want to prevent these three addresses from accessing your host. You would probably do something like this:
iptables -A INPUT -s 192.168.0.5 -p TCP -j REJECT
iptables -A INPUT -s 192.168.0.100 -p TCP -j REJECT
iptables -A INPUT -s 192.168.0.220 -p TCP -j REJECT
Alternatively you could do
iptables -A INPUT -s 192.168.0.0/24 -p TCP -j REJECT
but this would block 251 unrelated hosts, too. Not a good deal I’d say. Now, while the former alternative is annoying, what’s the problem with it? The problem is: It does not scale. Netfilter rules work like a fall-through trapdoor. This means whenever a packet enters the system, it passes through several chains and in each of these chains, netfilter checks all rules until either one rule matches or there are no rules left. In the latter case the default action applies. In netfilter terminology a chain determines when an interception to the regular packet flow occurs. In the example above the specified chain is INPUT, which applies to any incoming packet.
In the end this means every single packet which is sent to your host needs to be checked whether it matches the patterns specified in every rule of yours. And believe me, in a server setup, there are lots of packets flowing to your machine. Consider for example a single HTTP requests, which requires at very least four packets sent from a client machine to your web server. Thus, each of these packets is passing through your rules in your INPUT chain as a bare minimum, before it is eventually accepted or discarded.
This requires a substantial computing overhead for every rule you are adding to your system. This isn’t so much of a problem if you haven’t many rules (for some values of “many” as I am going to show). However, you may end up in a situation where you end up with a large rule set. For example, if you suffer from a DDoS attack, you may be tempted to block drone clients in your firewall (German; Apache2. Likewise: for Lighttpd). In such a situation you will need to add thousands of rules easily.
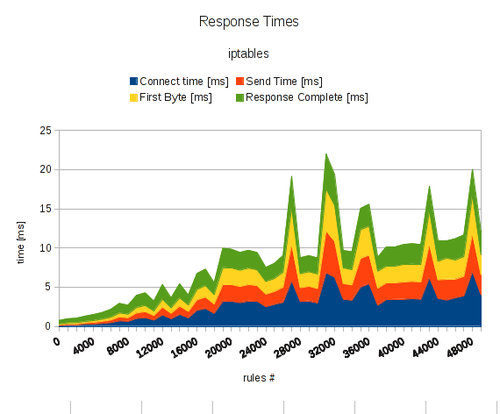
Being under attack, the performance of your server is poor already. However, by adding many rules to your firewall you are actually further increasing computing overhead for every request significantly. To illustrate my point, I’ve made some benchmarks. Below you find the response times of a HTTP web server while doing sequential requests for a single file of 10 KiB in size. I am explaining my measurement method in detail further below. For now, look the graph. It shows the average response time of an Apache 2 web server, divided into four parts:
connect time: this is the time passed by until the server completed the initial TCP handshake
send time: this is the time passed by which I needed to reliably send a HTTP request over the established TCP connection reliably (that means: one packet sent and waiting for acknowledged by the server)
first byte: this is time passed by until the server sent the first byte from the corresponding HTTP response
response complete: this is time passed by until the server sent all of the remaining bytes of the corresponding HTTP response (remaining HTTP header + 10 KiB of payload)
The netfilter framework, of which iptables is a part of, allows the system administrator to define rules for how to deal with network packets. Rules are grouped into chains—each chain is an ordered list of rules. Chains are grouped into tables—each table is associated with a different kind of packet processing.
Each rule contains a specification of which packets match it and a target that specifies what to do with the packet if it is matched by that rule. Every network packet arriving at or leaving from the computer traverses at least one chain, and each rule on that chain attempts to match the packet. If the rule matches the packet, the traversal stops, and the rule’s target dictates what to do with the packet. If a packet reaches the end of a predefined chain without being matched by any rule on the chain, the chain’s policy target dictates what to do with the packet. If a packet reaches the end of a user-defined chain without being matched by any rule on the chain or the user-defined chain is empty, traversal continues on the calling chain (implicit target RETURN). Only predefined chains have policies.
Rules in iptables are grouped into chains. A chain is a set of rules for IP packets, determining what to do with them. Each rule can possibly dump the packet out of the chain (short-circuit), and further chains are not considered. A chain may contain a link to another chain – if either the packet passes through that entire chain or matches a RETURN target rule it will continue in the first chain. There is no limit to how many nested chains there can be. There are three basic chains (INPUT, OUTPUT, and FORWARD), and the user can create as many as desired. A rule can merely be a pointer to a chain.
Tables
There are three built-in tables, each of which contains some predefined chains. It is possible for extension modules to create new tables. The administrator can create and delete user-defined chains within any table. Initially, all chains are empty and have a policy target that allows all packets to pass without being blocked or altered in any fashion.
filter table — This table is responsible for filtering (blocking or permitting a packet to proceed). Every packet passes through the filter table. It contains the following predefined chains, and any packet will pass through one of them:
INPUT chain — All packets destined for this system go through this chain (hence sometimes referred to as LOCAL_INPUT)
OUTPUT chain — All packets created by this system go through this chain (aka. LOCAL_OUTPUT)
FORWARD chain — All packets merely passing through the system (being routed) go through this chain.
nat table — This table is responsible for setting up the rules for rewriting packet addresses or ports. The first packet in any connection passes through this table: any verdicts here determine how all packets in that connection will be rewritten. It contains the following predefined chains:
PREROUTING chain — Incoming packets pass through this chain before the local routing table is consulted, primarily for DNAT (destination-NAT).
POSTROUTING chain — Outgoing packets pass through this chain after the routing decision has been made, primarily for SNAT (source-NAT).
OUTPUT chain — Allows limited DNAT on locally-generated packets
mangle table — This table is responsible for adjusting packet options, such as quality of service. All packets pass through this table. Because it is designed for advanced effects, it contains all the possible predefined chains:
PREROUTING chain — All packets entering the system in any way, before routing decides whether the packet is to be forwarded (FORWARD chain) or is destined locally (INPUT chain).
INPUT chain — All packets destined for this system go through this chain
FORWARD chain — All packets merely passing through the system go through this chain.
OUTPUT chain — All packets created by this system go through this chain
POSTROUTING chain — All packets leaving the system go through this chain.
In addition to the built-in chains, the user can create any number of user-defined chains within each table, which allows them to group rules logically.
Each chain contains a list of rules. When a packet is sent to a chain, it is compared against each rule in the chain in order. The rule specifies what properties the packet must have for the rule to match, such as the port number or IP address. If the rule does not match then processing continues with the next rule. If, however, the rule does match the packet, then the rule’s target instructions are followed (and further processing of the chain is usually aborted). Some packet properties can only be examined in certain chains (for example, the outgoing network interface is not valid in the INPUT chain). Some targets can only be used in certain chains, and/or certain tables (for example, the SNAT target can only be used in the POSTROUTING chain of the nat table).