Slow Down Internet Worms With Tarpits

Worms, worms are everywhere! The recent and prolific spread of Internet worms has yet again demonstrated the vulnerability of network hosts, and it’s clear that new approaches to worm containment need to be investigated. In this article, we’ll discuss a new twist on an under-utilized technology: the tarpit.
The Worms
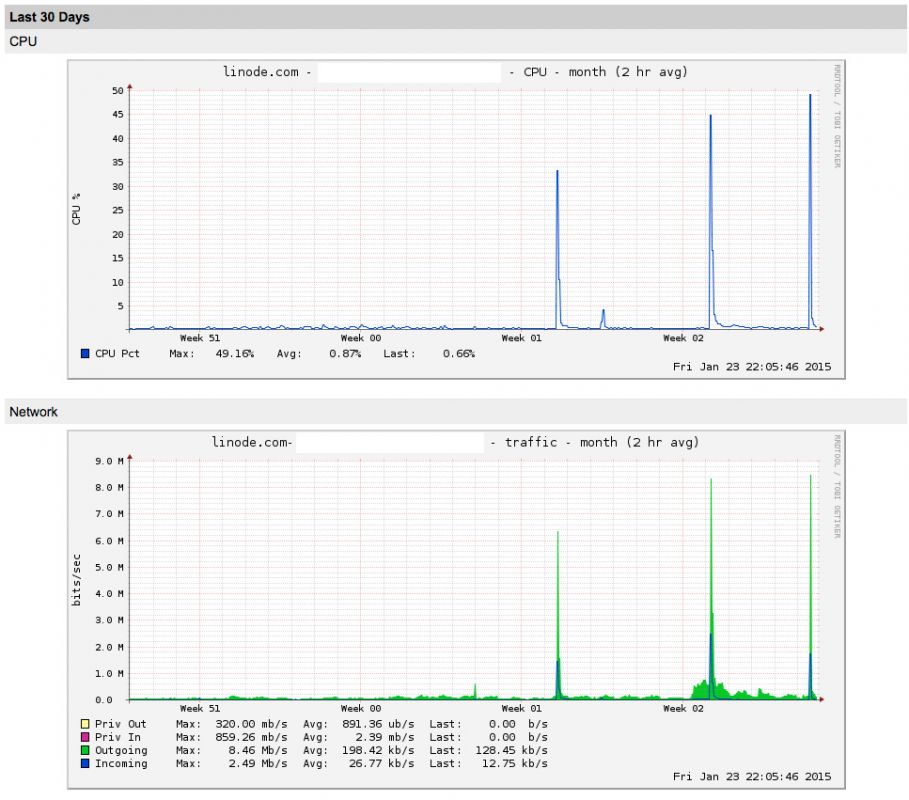
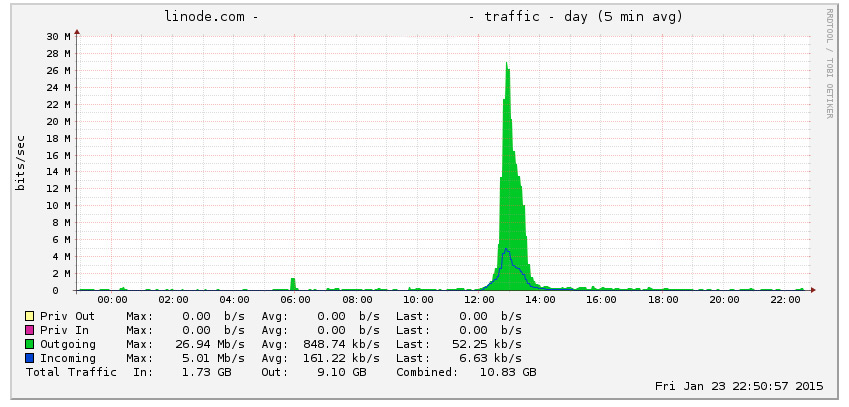
In a nutshell, worm technology works by infecting a host and then using it to scan for more victims. The damage caused by the recent worm outbreaks isn’t so much to the victim computer as it is to the networks in which they operate. The side-effect of propagation is that massive amounts of bandwidth are consumed as the infected hosts perform their scanning. The speed at which they are able to compromise new hosts grows exponentially, eventually causing a network meltdown.
In the future, worms could carry more damaging payloads, doing things like deleting files, installing network sniffers, or stealing confidential files. However, there is a fine balance between being overly destructive and fast to propagate, because just like in nature, a worm or virus that kills its host too quickly cannot effectively spread.
Solutions?
Preventative measures provide the most effective protection — in this case, patching the vulnerable systems before the worm is released. In the case of the Blaster worm, a patch was available long before the worm happened, and long enough for security experts to place informal « bets » as to when the worm would actually appear. However, in large companies and organizations with traveling users, applying and supporting a patch to systems can become somewhat of a tactical nightmare. So, given that preventative maintenance obviously isn’t working, it may be necessary to begin to examine some of the other possibilities for slowing the spread of worms, once outbreaks occur.
One such solution, and the focus of this article, is the TARPIT — which is available as a relatively new patch to the Netfilter (IPtables) firewall for Linux, in addition to being available for Windows platforms, Solaris, and OpenBSD thanks to the LaBrea tarpit project from Hackbusters (but now hosted on Sorceforge). For simplicity, this article will focus on just the IPtables version. What the tarpit project means to IPtables users is that now, instead of simply logging and dropping packets, they can now be sent to a TARPIT.
The concept behind a tarpit is fairly simple. The connections come in, but they don’t get back out. IPtables handles this by allowing a tarpitted port to accept any incoming TCP connection. When data transfer begins to occur, the TCP window size is set to zero, so no data can be transferred within the session. The connection is then held open, and any requests by the remote side to close the session are ignored. This means that the attacker must wait for the connection to timeout in order to disconnect. This kind of behavior is bad news for automated scanning tools (like worms) because they rely on a quick turnaround from their potential victims.