It can be helpful to configure Mac OS X to automatically mount shared network drives, this is particularly true for those of us who regularly connect to a network drive for file sharing or backups.
Setting up automatic network drive connections in OS X is a two-step process, you must mount the drive, then you add it to your automatic login items. This should work flawlessly in most versions of OS X, but we’ll cover an alternative approach that uses Automator to mount a network drive automatically on login as well.
1) Mounting the Network Drive
If you’re already familiar with mapping a network drive in Mac OS X you can skip the first part of this and go straight to System Preferences in the second section.
From the OS X desktop, pull down the “Go” menu and select “Connect to Server”
Connect to the server and mount the drive you want to automatically connect to on boot
Choose Guest or for a specific user check the box next to “Remember this password in my keychain” – you must select to remember the password otherwise the automatic login event can not happen without logging into the network drive
Next, you add the network drive to automatically connect on OS X by bringing it into your Login Items list.
Copy files or directories from one location to an another host by rsync.
If you’d like to set rsync automatically by cron or others, it need to configure like follows because authentication is required without settings. For example, Copy files or directories under the [/root/work] on dlp.srv.world to [/home/backup] on www.srv.world.
[1] Configure on source host.
root@dlp:~# apt-get -y install rsync
root@dlp:~# vi /etc/rsync_exclude.lst
# specify files or directories you'd like to exclude to copy
test
test.txt
[2] Configure on destination host.
root@www:~# apt-get -y install rsync
root@www:~# vi /etc/default/rsync
# line 8: change
RSYNC_ENABLE=true
root@www:~# vi /etc/rsyncd.conf
# create new
# any name you like
[backup]
# destination directory to copy
path = /home/backup
# hosts you allow to access
hosts allow = 10.0.0.30
hosts deny = *
list = true
uid = root
gid = root
read only = false
root@www:~# mkdir /home/backup
root@www:~# systemctl start rsync
[3] It’s OK. Execute rsync on Source Host like follows.
root@dlp:~# rsync -avz --delete --exclude-from=/etc/rsync_exclude.lst /root/work/ www.srv.world::backup
# Add in cron if you'd like to run reguraly
root@dlp:~# crontab -e
# for example, run at 2:00 AM in a day
00 02 * * * rsync -avz --delete --exclude-from=/etc/rsync_exclude.lst /root/work/ www.srv.world::backup
Fortunately, Mac Leopard users have a program called Time Machine that makes things a lot easier. But is Time Machine the perfect backup solution? I don’t think so. There are a couple of things that make Time Machine very unsuitable for me:
You need to get a seperate external hard drive that can only be used for Time Machine (and has to be formatted first)
That drive has to be formatted in HFS+, hence, without any (commercial) third-party plugins it’s not readable on Windows or Linux systems
You have to leave your drive on all the time to make sure Time Machine makes backups
You can’t make a list of things you want to have backed up, you can only exclude folders from your complete hard disk
Time Machine makes an exact copy of your hard drive
Especially that last ‘feature’ is very irritating to me. I have an external drive with about 300G of files, including lots of music and video files. My MacBook drive is only 80GB big, so i can never have the complete contents of my external drive on my MacBook. Let’s say i have 10GB of MP3 files, which i backup with Time Machine, then i remove about 5GB of files from my MacBook to free some space. What happens when the next backup round is happening? Exactly, the 5GB of files get deleted from the external disk as well. When i want to play a certain MP3 file from my external drive i now have to ‘restore’ and ‘look back in history’ to find it. Not very user-friendly.
Luckily, there is a very good (free) alternative to Time Machine that does exactly what i want with backups: it lets you specify which folders you want to backup, it doesn’t delete things on the backup drive when you delete files from your original drive, and it’s compatible with any external drive and can even backup files over a network. This piece of software is called rsync. Here’s how to use it.
rsync is a command-line utility shipped with every copy of Mac OS X. It originated from the UNIX/Linux world, where it has been part of most Linux distributions for many years. rsync is reliable, fast, and easily configurable. Try running it by opening up the Terminal.app (located in your Applications/Utilities folder) and running the command:
rsync
You’ll get an overview of all possible options. In essence the syntax is very simple:
rsync OPTIONS SOURCE DESTINATION
What you’ll probably want is a one-way transfer of all files in SOURCE to DESTINATION, where only files are copied that are not available on the DESTINATION disk or different. Aside from that you’ll want to include all subdirectories, links, permissions, date/time, groups, owner and devices. To do that simply use this easy-to-remember option list:
rsync -rlptgoD
Ha, just kidding! Fortunately there is another switch that does all of that with one switch, namely the archive switch:
rsync -a
So, let’s say you want to backup the files in your Documents directory to your external harddrive, which you appropriately named ‘backup’, then this would be the command:
rsync -a ~/Documents/ /Volumes/backup/Documents
For those of you who don’t use the Terminal very often: the tilde (~) is a shortcut for your home directory. If, for example, your name would be ‘Alice’ your home directory would probably be
Rsync is a program for synchronizing two directory trees across different file systems even if they are on different computers. It can run its host to host communications over ssh to keep things secure and to provide key based authentication. If a file is already present in the target and is the same as on the source the file will not be transmitted. If the file on the target is different than the one on the source then only the parts of it that are different are transferred. These features greatly increase the performance of rsync over a network.
Suppose you as a software developer has set up daily builds of your software for testing purposes. Every day you make a new build, users have to re-download the updated build to evaluate it. In this case you may want to enable differential downloads, so that users can download only difference between two builds, thereby saving on the server’s bandwidth. Users will also be happy as they don’t have to wait to re-download the whole thing. Similar situations are encountered when you want to set up a download archive which allows incremental sync for users.
In these cases, how would you distribute incrementally updated files efficiently for multiple users? In fact, there are open-source storage solutions that come with « delta sync » capability built-in, such as ownCloud or Syncthing. These kinds of full-blown solutions with built-in GUI require users to install a dedicated client, and thus may be an overkill for simple file distribution that you are looking for.
Barring full-blown third-party software like these, perhaps rsync may come to mind, which can do bandwidth-efficient file sync. The problem with rsync, however, is that all the heavy duty computations is done at the server side. That is, when a client requests for a file sync, the server needs to perform block-by-block checksum computation and search for blocks not available on the client. Obviously this procedure can place a significant strain on the server’s resources if the server needs to handle many users, and thus is not scalable.
What is Zsync?
This is when a command-line tool called zsync comes in handy. While zsync uses the same delta-encoding based sync algorithm as rsync does, it moves the heavy duty computation away from the server and onto the clients. What do I mean by that?
Well, in zsync, the server maintains a separate .zsync metadata file for a file to distribute, which contains a list of « precomputed » checksums for individual blocks of the file. When zsync client requests for a file sync, the client downloads .zsync metadata file first, and performs block-by-block checksum calculation to find missing blocks on its own. The client then requests for missing blocks using HTTP range requests. As you can see, the server is totally out of the loop from the sync algorithm, and simply serves requested file blocks over HTTP, which makes it ideal when incremental file sync is needed for many users.
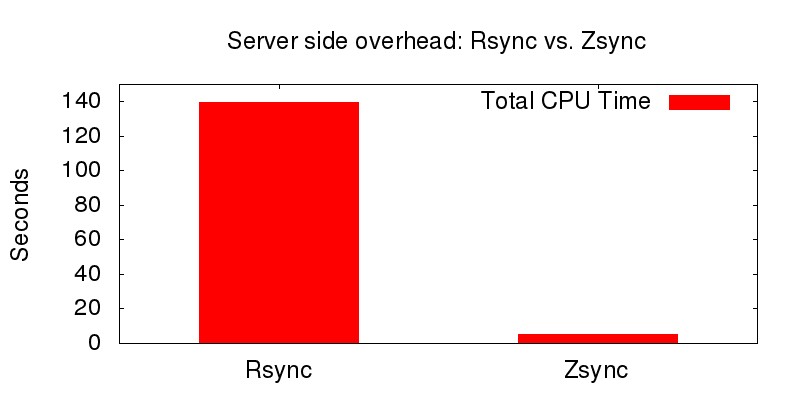
Here is a quick rundown on the server-side overhead difference between rsync and zsync. In the plot below, I compare rsync and zsync in terms of the server’s CPU usage when 200 users are downloading a tarball file with 2.5% discrepancy of a previous version. For fair comparison, SSH is not used for rsync.
With zsync, since all checksum computation overhead has shifted from the server to individual clients, the server overhead is reduced dramatically. A small neat idea makes zsync a real winner!
In the rest of the tutorial, I will show how to distribute a file incrementally using zsync under the Linux environment.
Zsync: Client Side Setup
On the client side, you need to install zsync to initiate file transfer from a remote web server. zsync is extremely lightweight, and is included in the most Linux distros. Here is how to install zsync on various distros.