MySQL Master / Slave Replication
11/10/2021 Comments off
Source: Uptime Made Easy
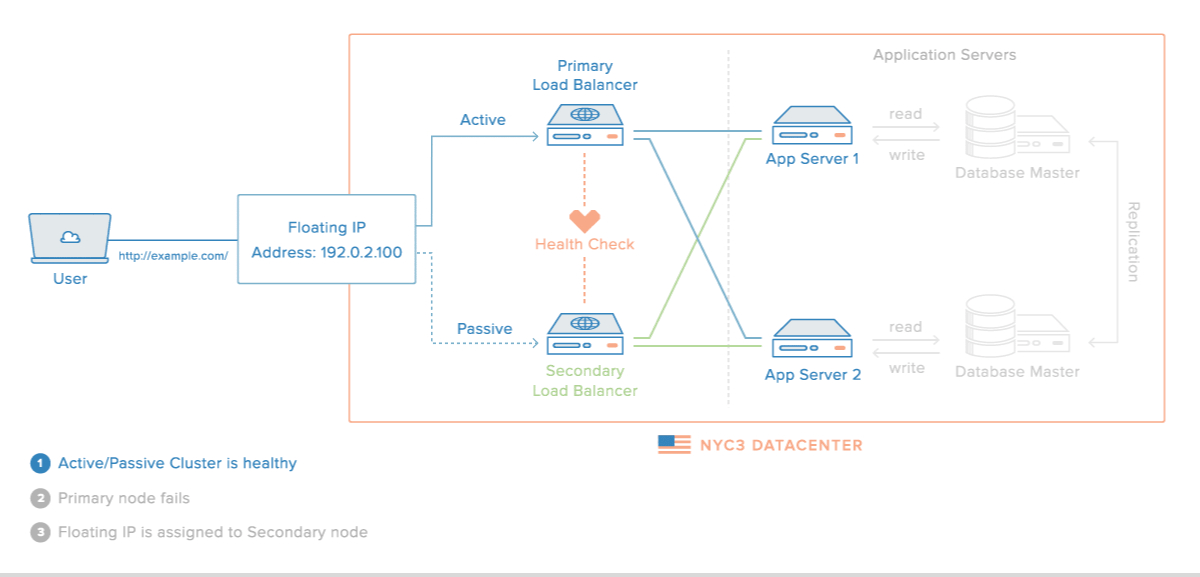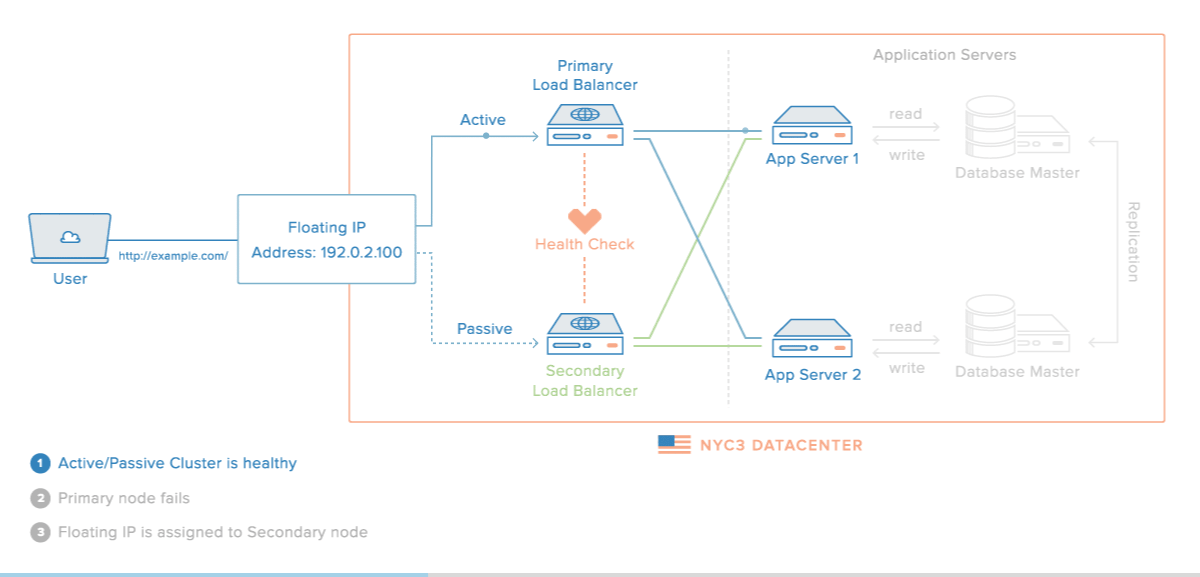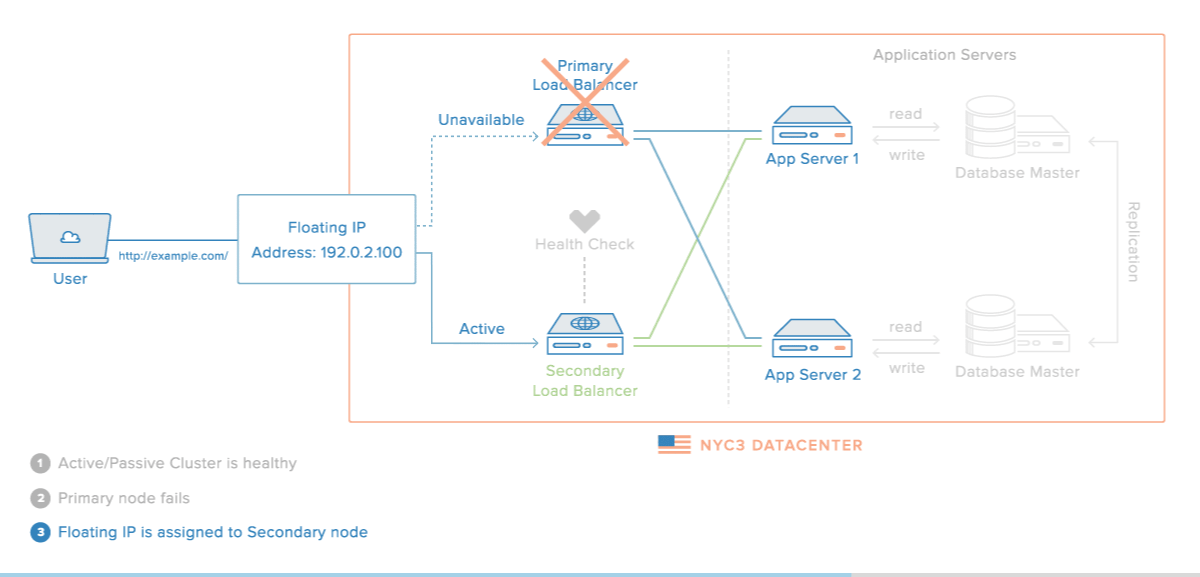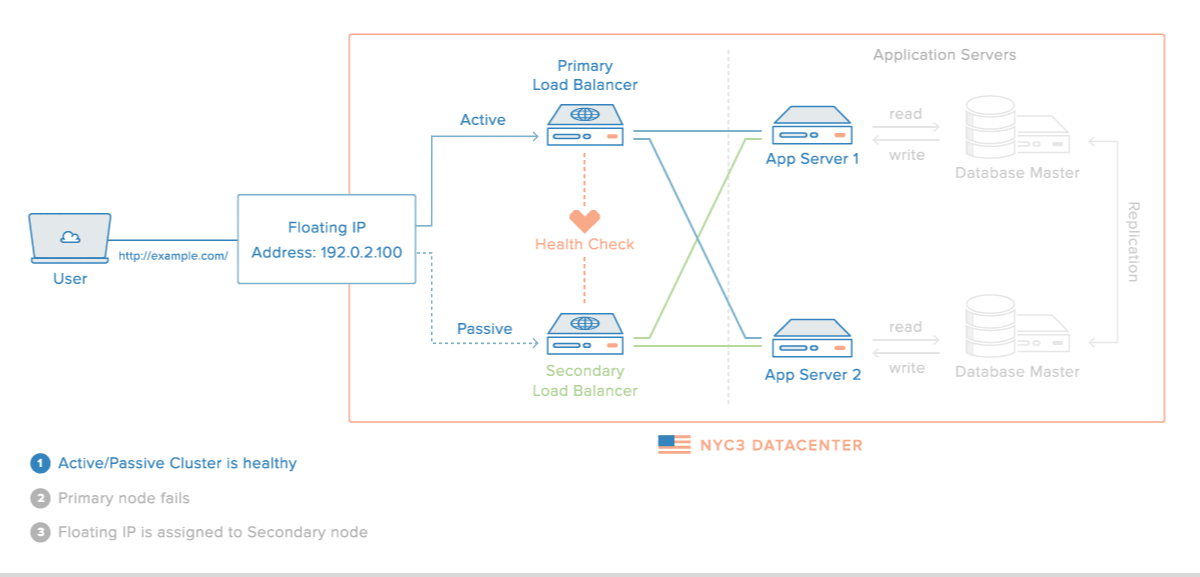
Master Slave MySQL Replication Summary
Master / Slave replication in MySQL is a great way to store an exact replica of your database on another machine in another location as part of a disaster recovery plan. Before setting up Master / Slave replication there are a few things to remember.
- Writes – Writes to the master database should make it to the slave. But writes to the slave will not make it to the master. If you do write records to the slave database directly, be prepared to have to either recreate the records or back them up separately and recover them if the replication breaks. Many times the only way to get the databases to replicate again is to backup the master and recover it over the top of the slave deleting anything that was in the slave database before.
- Broken Replication – Writes made directly to the slave can cause the replication to break due to duplicate key rows, etc.. Always write to the master.
- Reads – Reads should be possible from either server. Many organizations will use replication so as to create another database to read from thereby taking the load of all of their select statements and reports off the master server.
 Master Slave MySQL Replication
Master Slave MySQL Replication
Steps to Setup MySQL Master / Slave Replication
Prerequisites
We will be assuming that the following prerequisites are done prior to beginning the steps listed below:
- MySQL has been installed on both the master and the slave servers
- The slave server is able to communicate directly to the mysqld port (typically 3306) on the master server, meaning that there is no firewall, routing, NAT or other problems preventing communication.
- You have an administrator MySQL user that can create users on both the master and the slave machines.
- You have permissions to edit the /etc/my.cnf files on both machines and enough privileges to restart mysql.
That should be it! Let’s begin setting it up.