Zsync HTTP-based File Transfer Utility Transfers Large Files Efficiently
Zsync is an opensource file transfer utility built on top of rsync algorithm. This helps to download partial/differential files over the HTTP protocol. The utility allows downloading only new parts of a file from a centralized location, where the older version of the file is already within your computer.
While rsync is for syncing data from one computer to another, zsync allows file distribution, where the file hosted in a server using any web server can be distributed to many and downloaded seamlessly.
How it works
The command-line utility will do all the differential calculations in the client, instead of doing it in the server as in rsync. Server metadata will be created only once and stored as part of the control file. And rest of the operations and decision making will be handled by the client-side application. This will reduce the huge processing needed on the server-side, even when thousands of clients are trying to fetch the file.
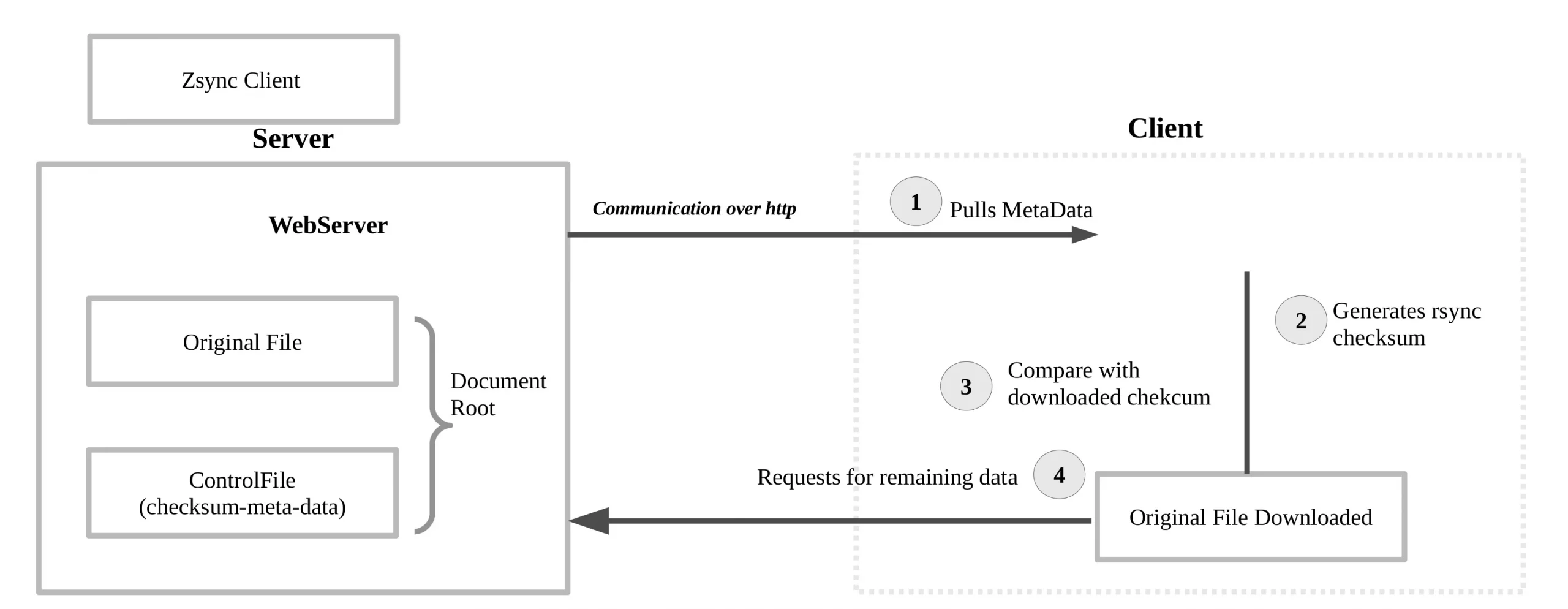
Zsync WorkFlow
Server
The server will calculate the checksum and create the control file in advance. This contains checksums, block size of the file, length and file permissions. Since the rest of the comparisons happens at the client-side, there aren’t any checksum calculations happening on the server, and each time the client requests for data.
Client
The Zsync client is written in “C”, and capable of pulling the metadata from the server first. This will compare with the current files checksum data (generated by rsync) and requests the remaining data from the server. Lire la suite…