Collect & visualize your logs with Logstash, Elasticsearch & Redis
Source: michael.bouvy.net
Update of December 6th : although Logstash does the job as a log shipper, you might consider replacing it with Lumberjack / Logstash Forwarder, which needs way less resources, and keep Logstash on your indexer to collect, transform and index your logs data (into ElasticSearch) : check out my latest blog post on the topic.
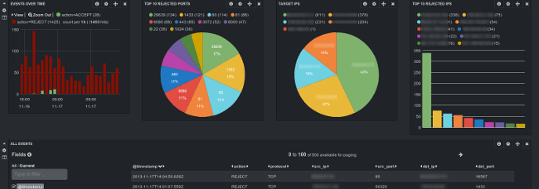
Kibana Dashboard
Even if you manage a single Linux server, you probably already know how hard it is to keep an eye on what’s going on with your server, and especially tracking logs data. And this becomes even worse when you have several (physical or virtual) servers to administrate.
Although Munin is very helpful monitoring various informations from my servers / VMs, I felt the need of something more, and bit less static / more interactive.
There are 3 kind of logs I especially wanted to track :
- Apache 2 access logs
- iptables logs
- Syslogs
After searching arround on the internet for a great tool that would help me, I read about the open source log management tool Logstash which seems to perfectly suit a (major) part of my needs : logs collecting / processing.
For the purpose of this post, I will take the following network architecture and assume and I want to collect my Apache, iptables, system logs from servers 1/2/3 (“shippers”) on server 4 (“indexer”) and visualize them :
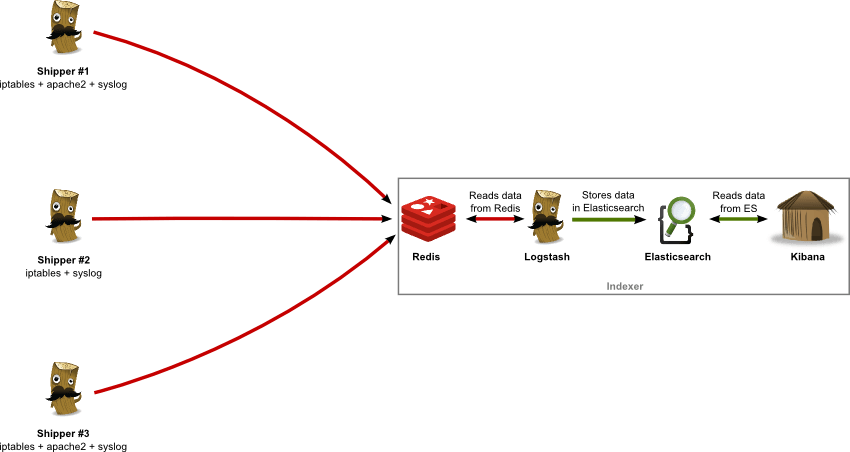
As you can see, I am using 4 complementary applications, the role of each one being :
- Logstash : logs collector, processor and shipper (to Redis) on log “shippers” 1-3 ; logs indexer on server 4 (reads from Redis, writes to Elasticsearch)
- Redis : logs data broker, receiving data from log “shippers” 1-3
- Elasticsearch : logs data persistent storage
- Kibana : (time-based) logs data visualization (graphs, tables, etc.)


{kind=link}
{kind=link}